Background
In this challenge, you'll learn more about web crawler. As usual, let's start the instance via the Start button on the top-right, and browse the website.

When you conducting a web application pentest, it's a good practice to check the robots.txt file, as there might have some hidden directories or valuable information.
robots.txt is a txt file that tells search engine crawlers which URLs the crawler can access on their site. Search engine crawler or spider, is a type of bot that explore the web regularly to find pages to add to their site index. robots.txt is use for Search Engine Optimization, or SEO, it lets the site easier to find for the public.
Now, let's check the robots.txt on the instance's website.
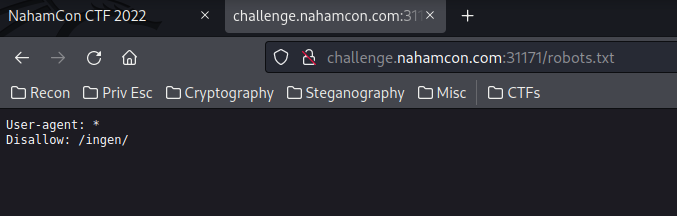
As you can see, there are 2 things here. User-agent: and Disallow:
User-agent:
User-agent tells you information about your device and operating system. Like it tells you about your browser's version, which browser you're using, your operating system, your CPU architecture. You can google What is my user agent if you're interested.
Example of my user agent: Mozilla/5.0 (X11; Linux x86_64; rv:91.0) Gecko/20100101 Firefox/91.0
In the above image, we can see User-agent: *, the * means all user agents are allowed, all crawlers can access to the site.
Disallow:
Disallow means disallowing crawlers to access a specific directory. In this challenge, we can see /ingen/ is disallowed, which means crawlers can't access to /ingen/ directory. BUT we can access to that directory, except crawlers.
So now why not go to /ingen/ to see are there any sensitive information?
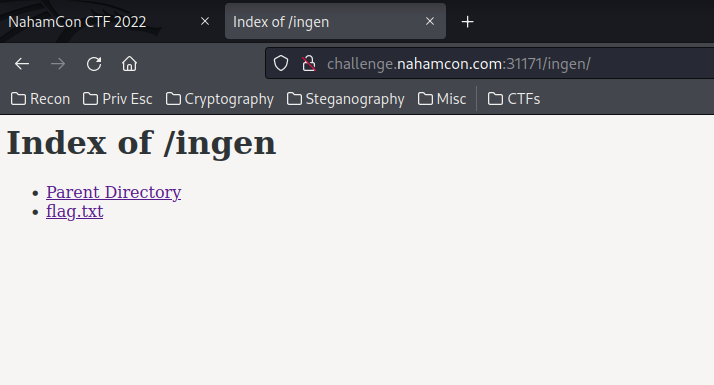
Wow!! We did see a flag.txt!! Let's click that file!
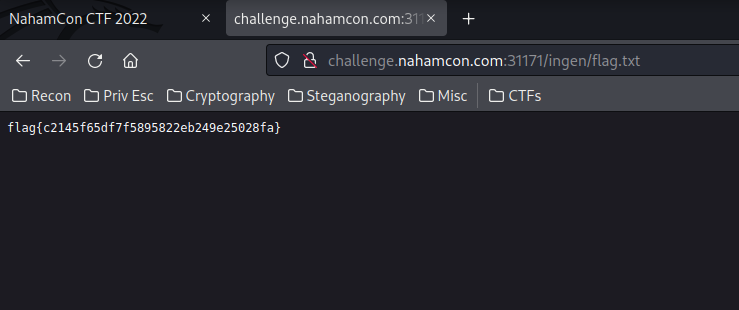
And here's the flag!